1In Part I, you will learn about the specifics of working with parliamentary data and understand the various parts of ParlaMint.
Parliamentary data in Social Sciences and Humanities research
1The active use of parliamentary data constitutes an important approach to advancing knowledge within the Social Sciences and Humanities (SSH). Increasingly, researchers turn to such data as a multidisciplinary treasure trove to explore not only political processes but also a wide spectrum of societal concerns, making parliamentary records valuable to fields such as linguistics, discourse analysis, sociology, history, law, and gender studies. Parliamentary proceedings are particularly noteworthy, as they document the work of elected representatives whose proposals, speeches, and voting behaviour have a direct impact on public life. These records allow scholars to identify and investigate the most salient societal concerns at any given time, while also providing a basis for evaluating and monitoring the performance of Members of Parliament (MPs).
2Although parliamentary proceedings have long served as research material in SSH domains, earlier studies were typically constrained by the limited volume of text that could be processed manually. The emergence of parliamentary corpora has transformed this landscape by making large datasets available (see CLARIN Resource Families) and by facilitating access to more comprehensive search results through concordancers and other tools that accommodate varying levels of technical expertise. This increased accessibility has expanded the potential of parliamentary corpora for use across a wide range of SSH disciplines and within diverse methodological frameworks. Importantly, parliamentary corpora, such as ParlaMint, are often enriched with multiple layers of annotation and metadata, enabling users to explore complex research questions engaging multiple parameters – for instance, linking linguistic features to sociodemographic information or connecting semantic annotation with patterns of political communication. Tools such as concordancers support mixed-method approaches, allowing scholars to combine distant reading, which reveals overarching patterns, with close reading, which captures fine-grained details crucial to the interpretative work in SSH disciplines.
3Accordingly, parliamentary corpora offer a versatile foundation for a range of research objectives. They enable the examination of specific linguistic phenomena characteristic of parliamentary discourse, while also opening up avenues for analysing broader aspects of politics and society. For example, such corpora support in-depth studies of policy-making processes, parliamentary culture, and political agendas. They also provide a basis for exploring how societal and cultural dynamics are articulated and negotiated in political speech. They are particularly well suited to tracing the emergence, evolution, and circulation of concepts and thematic frameworks in political discourse – both across time and across different parliaments. In addition, they furnish valuable material for uncovering communication strategies and deliberation techniques, shedding light on how parliamentary discourse both mirrors and actively shapes the social world.
Further reading
1Some concrete examples of using parliamentary data in SSH research are provided in overviews (Skubic & Fišer, 2022a, 2022b, 2024; Abercrombie & Batista-Navarro, 2020), academic papers (Kryvenko, 2025a, 2025b) and edited volumes (Ihalainen, Palonen & Ilie, 2016; Bayley, 2004).
Working with Parliamentary Corpora: Transcripts, Proceedings, and Comparative Insights
1Analysing parliamentary discourse requires careful attention to the nature of the source material, contextual factors – such as formal and informal rules of debate, speaker position and affiliation, audience dynamics, and speech topical framing – as well as the interpretative frameworks applied. In this chapter, we look into three foundational aspects that underpin the study of parliamentary discourse: the use of parliamentary transcripts as linguistic data and metadata, the interpretation of parliamentary proceedings as evidence of institutional activity, and the value of a comparative perspective for identifying patterns across time, parliaments and political systems. By situating speeches within their political and institutional environments and reflecting on the nature of the data itself, researchers can avoid reductive conclusions and more fully harness the analytical potential of parliamentary corpora for SSH research.
Source data
1Parliamentary transcripts constitute a rich yet complex source of data, often including varying levels of metadata and considerable diversity in content and format across countries and historical periods. Records of parliamentary activity have long been produced to ensure accountability and continuity, enabling both officials and the public to monitor decisions made within the legislative arena. Given the central role of parliaments in the political structures of most contemporary states, it became customary to maintain written documentation of their proceedings. However, official transcripts of debates were not universally available from the outset. In many contexts, parliamentary debates were initially documented only in abbreviated or paraphrased reports, often compiled by journalists and published in newspapers rather than disseminated by the institution itself. For example, unofficial accounts of the debate held on 16 October 1883 were printed in Slovenec (1873–1945), a newspaper subtitled as political newspaper for the Slovene nation (available through the sPeriodika corpus).
2Today, most parliaments provide free access to their official transcripts in response to growing public demands for transparency. However, these transcripts are published in a wide range of formats and hosted on websites with varying structures, which complicates both retrieval and processing. This poses challenges not only for individual researchers but also for compilers of large-scale resources, such as ParlaMint corpora. In light of these challenges, it is often more practical for researchers to incorporate already existing, high-quality data resources into their work rather than undertaking the laborious task of sourcing and standardising raw materials themselves.
Further reading
1Challenges of processing parliamentary records, particularly regarding their acquisition, cleaning and annotating, are discussed in detail, e.g., for the Swiss Federal Assembly (Salamanca et al., 2024). The compilation of versions of the national corpora incorporated into the ParlaMint project is described for the Assembly of the Republic of Slovenia (Pančur & Erjavec, 2020), the Senate of the Italian Republic (Agnoloni et al., 2022), the Austrian Parliament (Wissik & Pirker, 2018), the Czech Chamber of Deputies (Kopp et al.,2021), the Parliament of Iceland, or Althingi (Steingrímsson et al., 2020), and the Vekhovna Rada of Ukraine (Kryvenko and Kopp, 2023).
Parliamentary proceedings as evidence of parliamentary activity
1Another methodological concern relates to the faithfulness of the transcripts. Official parliamentary proceedings are typically produced according to transcription conventions, which vary across countries and are not always explicitly codified. In most cases, the transcripts aim to convey a faithful record of what was said, but they often omit features of spontaneous speech such as false starts, hesitations, repetitions, or background interjections. As a result, while the text provides a reasonably reliable representation of parliamentary talk, it does not capture every pragmatic nuance of oral delivery (see Voices of Parliament, ch. 4.2 by Fišer & Pahor de Maiti, 2021).
2The availability of written transcripts may also create the impression that parliamentary discourse is a purely textual phenomenon, when in fact it is inherently multimodal. Parliamentary speech is delivered live before multiple audiences: fellow MPs, institutional actors such as clerks and presiding officers, the media, and, indirectly, the electorate. Its effectiveness is therefore shaped not only by what is said, but also by how it is said, how it is received, and how it is mediated. Elements such as intonation, gesture, irony, sarcasm, or audience reactions may significantly affect the meaning of an utterance but are generally lost in the textual record. Researchers must therefore carefully consider whether their research questions can be adequately answered on the basis of written transcripts alone, or whether access to audio-visual recordings is necessary. For the purposes of this digital textbook, we focus on use cases that can be reliably addressed with textual data alone. It is worth noting, however, that new initiatives, like ParlaSpeech, have emerged that seek to fill this gap by aligning speech signals with their corresponding transcripts. Such developments hold considerable promise for future research, particularly for scholars interested in the pragmatics and performative dimensions of parliamentary discourse.
Further reading
1Variation in theoretical perspectives on parliamentary records, key tensions in the making and editing of the official parliamentary transcripts as well as the process of producing the official parliamentary transcripts are discussed, e.g., with respect to Finnish (Voutilainen, 2023), British (Mollin, 2007; Slembrouck, 1992), or European and Japanese (Kawahara, 2024) parliaments.
The comparative perspective
1Parliamentary proceedings form part of a broader genre of political discourse, which also includes speeches delivered outside parliament, such as campaign addresses or MPs’ posts on social media. Within this larger sphere, parliamentary discourse itself constitutes a distinct subgenre, and, as noted earlier, it further divides into several internal subgenres. Illie (2015) identifies some of the more representative ones, which are typical of Westminster-system parliaments: ministerial statements, interpellations, parliamentary speeches, parliamentary debates, oral and written parliamentary questions, and question time. Each of these fulfils different institutional goals and follows specific rules of interaction. For instance, an interpellation is a formal procedure designed to question the government about its actions, while a parliamentary speech typically presents a party's or individual's position. Because of their divergent purposes and conventions, these subgenres are not directly comparable in linguistic terms. For example, the pragmatic weight of a question asked during question time differs considerably from that of a statement in a plenary speech, even if both are formally part of parliamentary discourse.
2Beyond internal variation, comparative research also needs to account for the differences produced by parliamentary culture across national contexts and historical periods. Parliamentary culture encompasses the traditions, norms, behaviours, and institutional practices that shape how parliaments are formed and how they function. It reflects a complex interplay between formal rules – such as procedures, debate structures, or turn-taking conventions – and informal customs, including rhetorical styles, patterns of interaction, or the expectations associated with particular roles. These practices are influenced not only by internal dynamics but also by broader social forces, such as public opinion and media attention.
3It is important to recognise parliaments as highly conventionalised communicative settings. Institutional procedures affect almost every aspect of discourse, from the structure and content of debate to forms of address, the use of set phrases, and the preferred style of deliberation, e.g., free interventions versus pre-prepared speeches, admissibility of interruptions). Such conventions differ across parliaments, though certain overlaps can be observed among those with shared traditions. In fact, sociohistorical developments and cultural traditions exert a strong influence on debating styles. A broad, if somewhat simplified, distinction can be drawn between Westminster-type parliaments, where debate tends to be adversarial and confrontational, and Western European consensus-oriented parliaments, which promote a more deliberative and cooperative style. Comparative research must remain attentive to such differences: what appears as a dominant rhetorical strategy in one context may be exceptional in another, and methods must be adapted accordingly.
4Awareness of both national specificity and cross-national similarity is therefore essential in comparative studies of parliamentary discourse, but it is equally important to understand that research design is constrained by the affordances of the available corpus data: each national ParlaMint corpus covers a different timespan, provides varying levels of speaker metadata, and may differ in the annotation of socio-demographic information (such as the presence or absence of speaker birthdates). While ParlaMint is unique in its aim to maximise comparability across languages and contexts, the scope of information ultimately depends on what is provided by the individual parliamentary institutions. These differences directly shape which metadata could be incorporated into the final corpus and, consequently, which metadata categories can meaningfully serve as parameters in cross-parliamentary comparative studies.
Further reading
1Ilie (2017) outlines the differences between Westminster-model and European-model parliaments, describes the parliamentary discourse genre and its subgenres, and reviews key research topics on parliamentary debates. Taylor (2022) summarises recent applications of corpus linguistics in the study of political discourse, including parliamentary debates. Taylor & Del Fante (2020) offer a comparative perspective on corpus-assisted discourse studies and reflect on comparing the use of culturally loaded words, semantic groupings, discourse frames and rhetorical features across languages.
The ParlaMint project
1ParlaMint was a CLARIN ERIC flagship project, which turned parliamentary proceedings, i.e. official records of debates, questions, proposals and other formal actions by members of parliament (MPs) and participants such as governmental officials or guests, into cutting-edge comparable and interoperable FAIR data resources suitable for research in SSH, various teaching contexts, journalism and media, policy analysis and public engagement. The compilation of the ParlaMint corpora took place in several stages and led to the development of related projects.
ParlaMint I and ParlaMint II: a retrospect
1The ParlaMint project started in November 2019 as an initiative of the core partners, who developed and tested the workflow on their corpora (Bulgarian, Croatian, Polish, Slovenian) and released version 1.0 primarily as a model to guide the work of the new partners. Work continued in the ParlaMint I project (2020–2021), which produced corpora of 17 European national and regional parliaments released as versions 2.0 and 2.1. These corpora contained two built-in subcorpora (COVID and Reference) as well as metadata on speeches (house, term, date) and speakers (name, gender, birth, if available, type, role and party name) (Erjavec et al., 2023).
2The ParlaMint II project (2022–2023) covered 29 European countries and autonomous regions, extending the time coverage as well as adding information on political orientation. The built-in subcorpora were expanded to three categories: COVID/War, COVID and Reference. Version 3.0 was an intermediate release, version 4.0 the final release, and version 4.1 a maintenance update completed after the project ended (Erjavec et al., 2025). Versions 3.0, 4.0 and 4.1 of the original language corpora were also machine-translated to English (Kuzman et al., 2024), where words and multi word expressions were tagged using the upgraded Ucrel Semantic Analysis System.
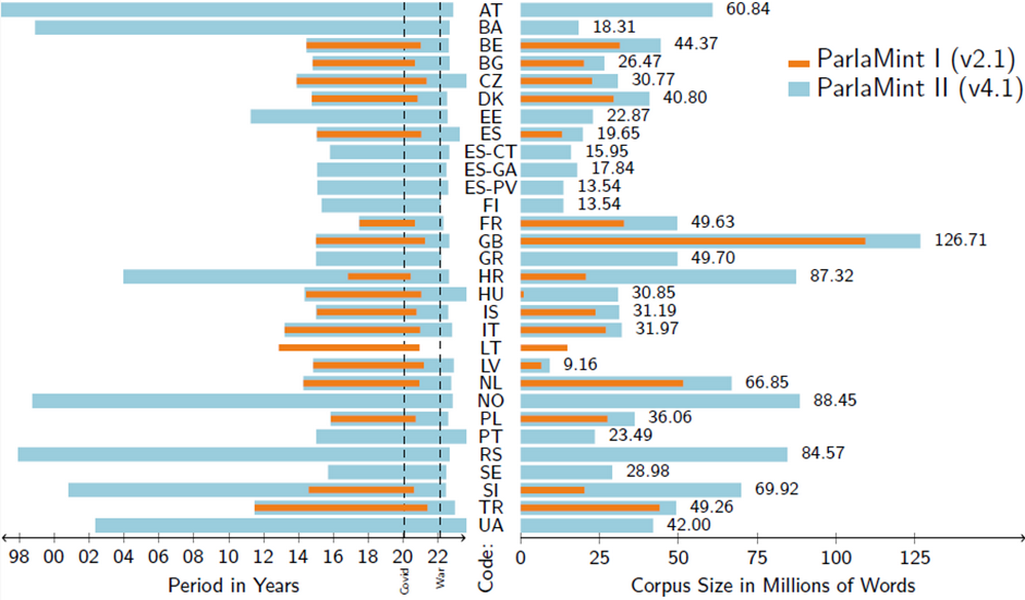
3Figure 1 shows the progress made between ParlaMint I (version 2.1) and ParlaMint II (version 4.1) in terms of the corpora included, showing two-letter country or region codes, corpus size in millions of words and the period covered in years.
Related projects: ParlaCAP and ParlaSpeech
1Building on the breadth of geographical coverage of the ParlaMint II corpora (Figure 2), the ParlaCAP project applies advanced natural language processing (NLP) to track political agendas and sentiments across parliamentary proceedings in the ParlaMint dataset. To do so, it engages the Comparative Agendas Project’s coding scheme based on a Master Codebook developed to harmonise a network of projects aiming to classify political agendas according to the policies they address (Bevan, 2019) using a set of 21 topics, e.g. Energy, Defence, Culture, Civil Rights and so on. For more detail, see Topic Information below.
2Moreover, under the ParlaCAP project, ParlaMint corpora are annotated for sentiment analysis via the ParlaSent deep learning model for multilingual sentiment analysis, which is built on XLM-R-parla, a domain-specific transformer based on XLM-Ro-BERTa-large “vanilla” model, and pre-trained on the parliamentary data (Mochtak et al., 2024). For more detail, see Sentiment information below.
3The ParlaCAP project is set to produce a structured, tabular dataset cross-referenced with the PartyFacts metadatabase on political party metadata and, where available, the V-DEM surveys on the state of democracies. This dataset will be made fully downloadable via CESSDA ERIC and accessible through major research infrastructures (CESSDA, CLARIN, and DARIAH), complemented by a graphical user interface and API to ensure broad usability.
4ParlaSpeech is another important initiative that grew directly out of the ParlaMint project. While ParlaMint focuses on text, ParlaSpeech extends this work by aligning transcripts with audio recordings of parliamentary sessions, thereby creating valuable speech–text datasets for under-resourced languages (Ljubešić et al., 2025).
5To date, the project contains parliamentary audio recordings in Czech, Polish, Croatian and Serbian. This selection of recordings responds to the uneven availability of speech resources across languages: a handful are well covered, some moderately, while many – including official EU languages – remain in the “long tail” with little to no data. For example, Polish has about 180 hours of public data, Serbian 12, and Croatian had none before ParlaSpeech.
6ParlaSpeech incorporates five distinct annotation layers: linguistic annotations (ParlaSpeech-Ling following Universal Dependencies), sentiment annotation (ParlaSpeech-Senti), filled pause identification (ParlaSpeech-Pause), precise word-level alignments (ParlaSpeech-Align), and primary stress markers (ParlaSpeech-Stress), although currently only linguistic, sentiment, and pause annotations are consistently applied to all the datasets in the project.
7These layered annotations are designed to support in-depth investigations into prosodic features, patterns of speech disfluency, and comprehensive multimodal analysis of parliamentary discourse. The corpus supports computational (JSONL), phonetic (TextGrid) and corpus linguistic (noSketch Engine) analysis formats.
8Key challenges identified include incomplete or inaccurate transcripts, missing or unreleased recordings, inconsistent metadata, and mismatched ordering between transcripts and audio, but the approach shows promise for expanding to many more languages.
The ParlaMint corpora
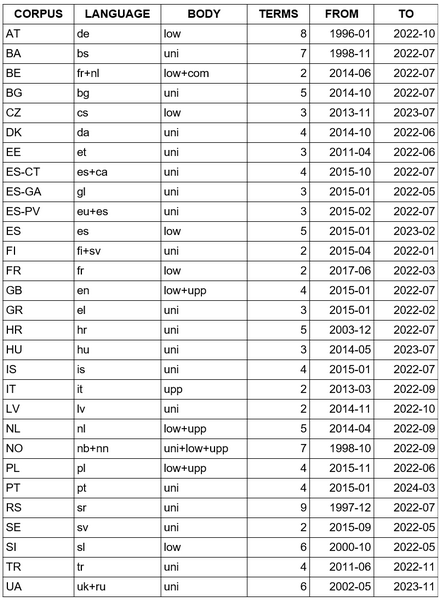
1As described in the previous section, the ParlaMint corpora are the result of two ParlaMint projects and subsequent initiatives. The following description is adapted to ParlaMint version 5.0. This version of the corpus contains parliamentary proceedings of plenary debates1 that were delivered in 29 European parliaments2 and 30 different languages between 2015 and mid-2022. Several national ParlaMint corpora, however, contain data spanning a much longer period. The ParlaMint corpora, together with their languages, parliamentary bodies (uni – unicameral parliament; upp – upper house; low – lower house; com – committees), number of terms and temporal coverage, are summarised below (see Table 1)..
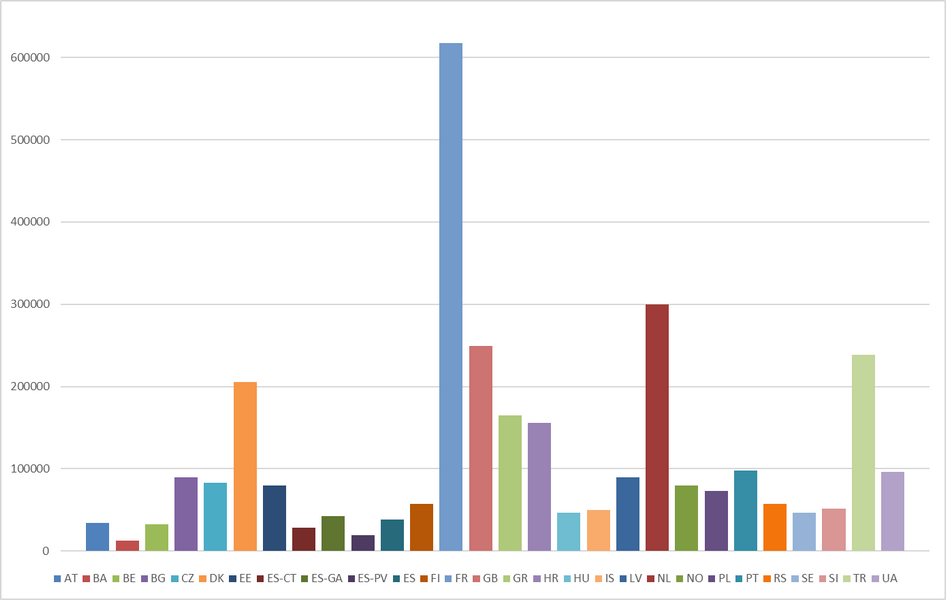
2Overall, ParlaMint contains over 8 million speeches consisting of more than 1 billion words. It should be noted that the timespan, the size as well as the sitting calendar and debating conventions greatly influence the amount of data available for a particular national corpus (see Figure 3). For instance, the Slovenian National Assembly consists of 91 MPs versus the French National Assembly that seats 577 MPs; the Turkish National Assembly has a longer recess period and met 106 times in 2021 compared to the Dutch House of Representatives which met 137 times in the same year.3
Data access
1ParlaMint corpora can be obtained by downloading the files or by accessing the preloaded data via online platforms – noSketch Engine and TEITOK. This digital textbook uses noSketch Engine4 in the showcases, so further details on how to use the tool will be given in Part II. This section provides some additional information on the download option and the TEITOK platform.
Corpus file download option
1ParlaMint files can be directly downloaded from the CLARIN.SI repository subject to Creative Commons - Attribution 4.0 International (CC BY 4.0) licence which allows free sharing and adaptation of data, but requires obligatory credit attribution. The files are available in different batches and several formats, namely as a TEI-encoded corpus, a linguistically marked-up corpus in several formats and a version machine-translated into English,5 all with added metadata files. The repository also offers a clear overview of different versions published throughout the years. In the case of direct download from the repository, the data can be processed by various desktop or online tools for data mining, like Orange 6 or Voyant.
Online tools with preloaded data – noSketch Engine and TEITOK
1For on-line analysis, the ParlaMint corpora are preloaded to noSketch Engine (Kilgarriff et al., 2014) and TEITOK 7 (Janssen, 2016), tools that enable open exploration of data.This digital textbook uses noSketch Engine in the showcases, so further details on how to use it are given in Part II. TEITOK, on the other hand, is not used in the showcases, so some general guidelines on how and when to use it are provided in this section.
TEITOK versus noSketch Engine
1While both tools, noSketch Engine and TEITOK support search, there are some important differences in the platforms that can guide the users in choosing one over the other. As will be seen in Part II, noSketch Engine is a powerful analytical tool that can handle advanced search queries and can produce different statistics. It enables various data filtering approaches that can help the user refine the results, save them (as subsets/subcorpora) and re-use them in subsequent analyses either in the tool or locally. As such, it is great for quantitative and qualitative research work over text. However, it is less well adapted for viewing the annotated extended context which is necessary for many interpretative tasks in qualitative research.
2While the results of search and statistical queries in noSketch Engine allow the researcher to expand the text of the proceedings, the range and display of the context is highly limited and cannot be navigated in a transparent way. So, noSketch Engine is typically the tool for advanced querying and analysis while TEITOK is the better choice when a clearer overview of context is needed, i.e. it is able to present a corpus as a highly-annotated digital edition. The two platforms are best understood as complementary resources, particularly valuable for researchers working with mixed-method approaches. 8
Main TEITOK features
1The TEITOK platform allows for a reader-friendly visualisation of the speeches, which can also display text annotations – in the case of ParlaMint, e.g., marked-up named entities, like persons, organisations, etc., or transcriber’s notes, as shown in Figure 4. As both tools, noSketch Engine and TEITOK use the same data,9 the user can view this information in both. However, as mentioned, the presentation of extended context is more reader-friendly in TEITOK. Moreover, links to source documents and easy transition between different sessions and speeches inside a debate are only available in TEITOK.

2For each of the national ParlaMint corpora, TEITOK also provides information about the corpus compilation process, data sources used, characteristics of the national parliament, etc. which can be helpful for any users of this particular data in their study designs and interpretation of the results (see, for example, the description page of the Ukrainian parliamentary corpus ParlaMint-UA). This information is not available in noSketch Engine and it is advisable to check the TEITOK entry page for the selected ParlaMint corpus even if the rest of the analysis is planned in noSketch Engine.
3Although the TEITOK interface is less well adapted for computing and viewing advanced statistical overviews as in noSketch Engine, it provides some lists and statistics that can help the user navigate through extensive data. Once you select the desired national ParlaMint corpus and enter its description page, you can quickly display a list of all people and organisations included in the transcripts or browse through individual parliamentary proceedings one after the other, or by a particular metadata category, such as term, sitting date or body (see Figure 5).
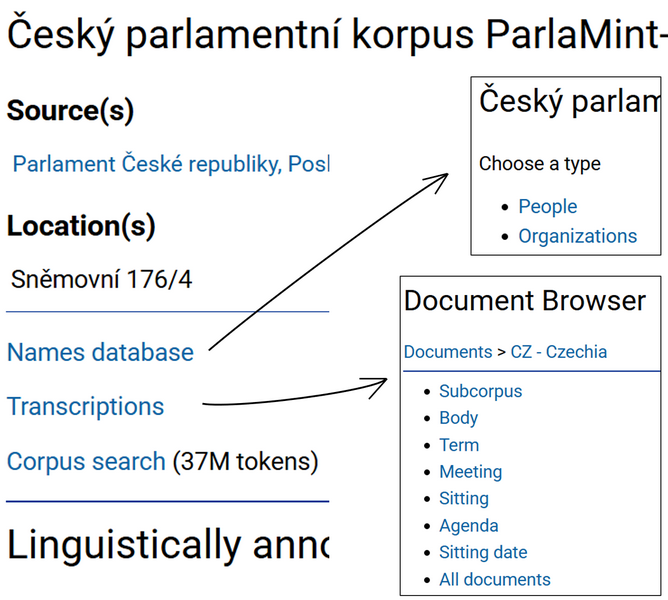
4Such lists are available also for a subset of data obtained through a search query (e.g., for a particular word (at the bottom of the results page in TEITOK), a user can list all parties with information on how frequently they used this word; the search functionality will be presented further down). However, these lists are less informative compared to those produced in noSketch Engine which (1) allow to display also relative frequencies that are usually needed because the compared groups are rarely of the same size, and (2) the lists in noSketch Engine provide a direct link to display the actual speeches thus serving as a filtering mechanism to get the most relevant data for the analysis. So, given a more powerful and possibly more intuitive and transparent user interface, it seems preferable to use noSketch Engine for any statistical tasks, and TEITOK for clear visualisations of context and information that cannot be displayed in noSketch Engine, like details on corpus compilation/people/organisations or links to external sources which can help in the contextualisation of the results (see Figure 6 as an example).10
5TEITOK is also equipped with a relatively strong search interface11 that allows building queries based on wordforms, linguistic annotation and/or metadata. The interface uses Corpus Query Language (CQL) to formulate queries, but for anyone not familiar with its syntax, it provides a query builder that facilitates query creation. As with statistical analyses, it seems that noSketch Engine has a somewhat easier and more powerful search interface than TEITOK. For this reason, we introduce the TEITOK interface only insofar as it helps locate the same section of a debate in both tools, thereby providing a more complete view of the context.
From noSketch Engine to TEITOK
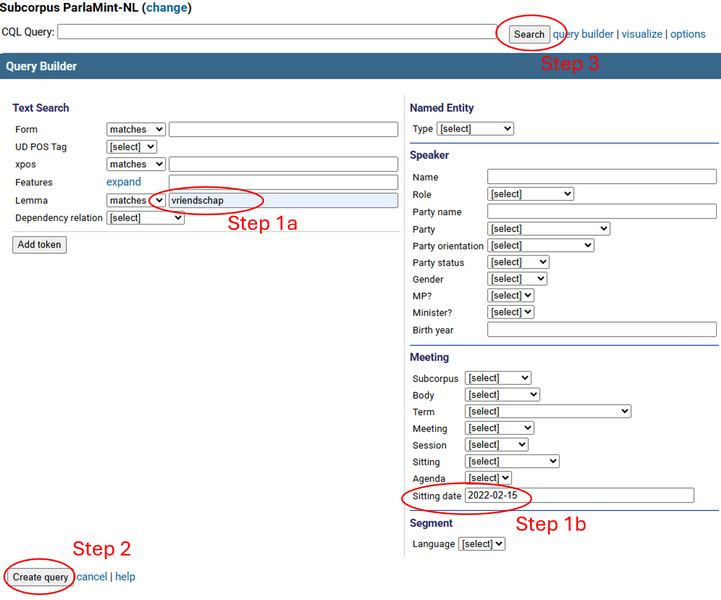
1Interpretation of the results usually requires good understanding of the context which is dependent on the scope of the available context as well as its legibility. To exploit the visualisation advantages of TEITOK and analytical capabilities of noSketch Engine, we can search for the exact same debate section in TEITOK that we have found in noSketch Engine. Detailed instructions on using noSketch Engine are provided in Part II, so for illustrative purposes only, let us focus on occurrences of the word vriendschap in the Dutch parliament (ParlaMint-NL) and decide we want to get more context for the concordance line 5 (Ja, in alle vriendschap, dat begrijp ikare … by Martin van Rooijen). By clicking the light grey area on the left part of the line, we find, among other details, the date of the speech (speech.date = 2022-02-15). In TEITOK, we will use our query term (vriendschap) together with the speech date to quickly locate the debate in which the selected sentence was delivered. This is, of course, just one of the possible search approaches.
2To do this, we need to perform the following actions:
- Open the TEITOK ParlaMint landing page, select Subcorpora in the menu on the left and then click ParlaMint-NL.
- From there, we choose Corpus search in the menu on the left and expand the query builder option located to the right of the search box.
- On the left, there is a Text search box. One of the fields is Lemma. We input our search word in this field (see Figure 7).
- On the right, there are fields to define metadata. We locate the field Sitting date and input the date which we copied from noSketch Engine metadata (2022-02-15).
- We then click Create query after which the query is written down to the search field, and we can click Search.
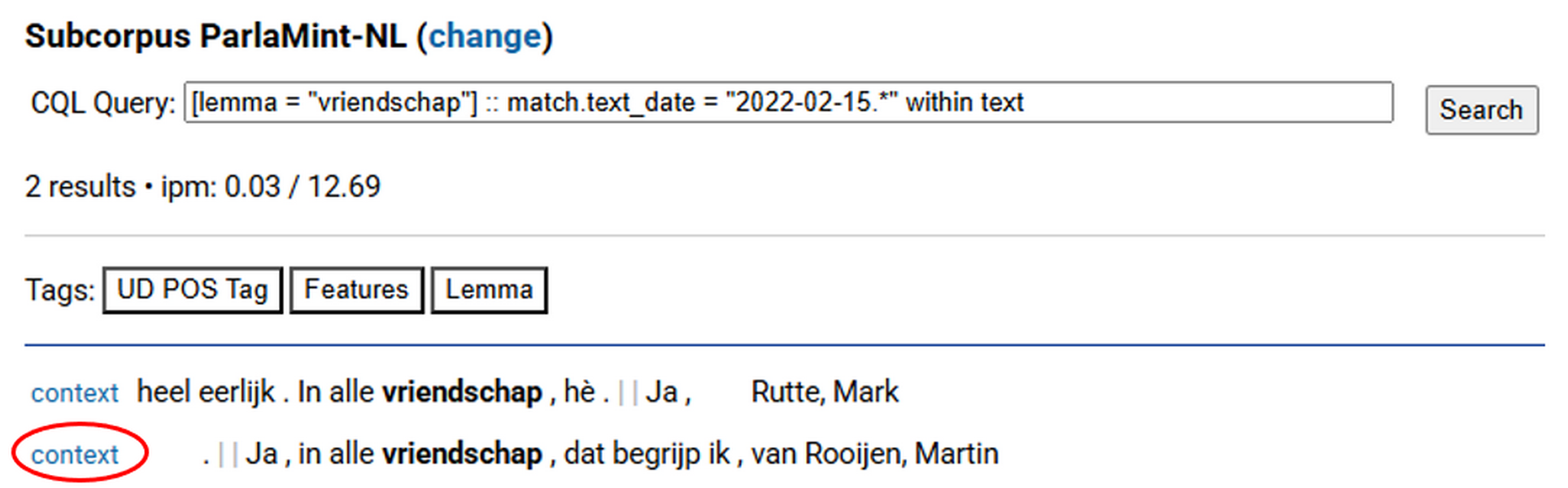
- The tool returns two hits. Since we wanted to explore the context of the concordance line 5 in noSketch Engine (Ja, in alle vriendschap, dat begrijp ikare … by Martin van Rooijen), it is the second hit in TEITOK that we are looking for.
- To display context, we click context on the left side of the selected row (Figure 8), and we are presented with M. van Rooijen’s speech in the context of the entire debate. To navigate between pages, i.e., from the beginning to the end of the debate, scroll to the top and use the left and right arrows next to the page number.
Corpus provenance, structure and annotations
1Individual ParlaMint corpora, as many other linguistic corpora, can be understood asstructured datasets that consist of several interrelated layers of information added to the original content. These levels include provenance information, structural markup, linguistic annotation and metadata. The following subsections describe these layers in the context of ParlaMint and draw on the representation used in noSketch Engine to familiarise the user with the tool and support its effective use.12
Provenance information
1The layer of provenance information describes the methodology and process of corpus compilation, providing transparency about how and by whom the data was collected, organised, processed, as well as by whom and to what means the corpus can be used. For ParlaMint, this information is available:
- in the CLARIN.SI repository that serves as an archive and versioning manager for the ParlaMint corpora. The ParlaMint landing page in the repository gives useful provenance information. Figure 9 and Figure 10 highlight some of the key fields: a pre-formatted text for easy citation and licence information, description and link to additional documentation, overview and access to different versions, as well as links to corpus files (the relevant repository page is accessible also through the noSketch Engine corpus information page via the Corpus description & bibliography button on the left of the screen);
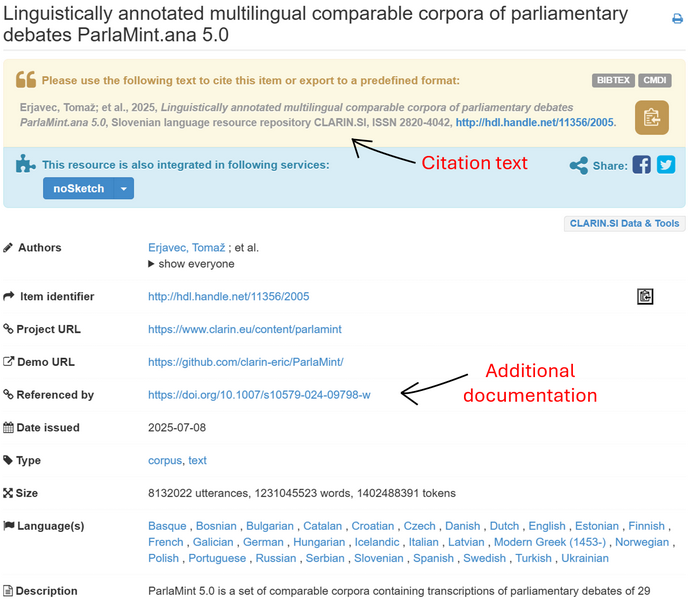

- in the TEITOK description page for ParlaMint and its individual parts as mentioned in Section Main TEITOK features
- in the scientific papers dedicated to ParlaMint compilation, namely Erjavec et al. 2023 and Erjavec et al. 2025
Structural markup
1The next layer of information consists of structural markup that captures the structural properties of the parliamentary proceedings, making it possible to analyse the documents at multiple levels of granularity. The structural markup is particularly important for corpus compilers in order to represent the internal structure of parliamentary proceedings in a consistent and machine-readable way. By encoding sessions, debates, speakers, and utterances, markup ensures that the corpus can be navigated, validated, and maintained across different parliaments and languages. For users, such structured markup is also highly valuable as it enables complex searches at different levels of textual granularity.
2In the case of ParlaMint, texts are encoded in TEI XML (Text Encoding Initiative XML), a widely used standard for representing textual data in a structured and machine-readable way. The encoding follows the ParlaMint schema which defines how the contents of the corpus, the actual speeches as well as all added details, are organised and named. Note that noSketch Engine uses data in the vertical format which is a derived, simplified representation of the TEI data, adapted for efficient loading and processing within the tool (see also Footnote12).
3The schema therefore not only defines the structural components into which the corpus texts are segmented (like sentences or paragraphs) but also provides a common predefined set of tags and their values that are filled with various information, like grammatical characteristics or metadata about speeches and speakers. Certain tags are constrained by closed typologies, e.g., speaker roles, political orientation, linguistic labels, while other tags accept open or unrestricted values, such as speaker names. A common schema like the one used in ParlaMint is a prerequisite for creating a comparable and interoperable set of corpora. To read more about the schema and the encoding process, see Erjavec & Pančur, 2022 , Erjavec et al., 2023 and Erjavec et al., 2025 .
Structural elements and tokenisation
1For each ParlaMint corpus, noSketch Engine provides a helpful information page (e.g., the information page for ParlaMint-PL which can be accessed from dashboard by clicking the Corpus info button or via the i-symbol at the top of the page) that outlines the main quantitative characteristics of the selected corpus, specifying its structural elements as well as listing the layers of linguistic annotation (see Section Linguistic annotation) and all metadata categories with its values (see Section Metadata). As an example, Figure 11 shows a part of this information page for ParlaMint-PL. We see frequency information that refer to all occurrences of a given structural element defined during structural markup. e.g., there are almost 230 thousand documents in ParlaMint-PL which refer to speeches and which are composed of more than 35 million words and some 10 million more tokens.

2In concordancers like noSketch Engine, which are intended for browsing and analysing the content of a linguistic corpus, the frequencies, when not specified otherwise, usually refer to tokens. A token represents a single occurrence of a running unit in the text between spaces, as defined by the concordancer’s tokenisation procedure. In the case of ParlaMint, tokens cover both words, which begin with a letter of the alphabet, and non-words, which include punctuation, numbers (see Figure 12) and tokens such as 3D or #SzczepimySię. This also explains the higher number of tokens in the corpus compared to words.

Linguistic annotation
1The next layer of information consists of linguistic annotations that outline linguistic properties of the parliamentary proceedings, making it possible to effectively analyse the language patterns.The linguistic annotation in ParlaMint includes lemmatisation , i.e., grouping all morphologically different forms of the same word to its base form, as well as annotation of word classes (also called parts-of-speech or PoS), morphosyntactic features and syntactic relations. The annotation of grammatical characteristics in ParlaMint follows commonly accepted tagsets based on the Universal Dependencies (UD) formalism . UD is an international framework for describing the structure of sentences in a consistent way across languages: it provides a standardised set of part-of-speech tags (verbs, nouns, adjectives, etc.), morphological features (number, case, tense, etc.), and syntactic relations (subject, object, modifier, etc.). This makes it possible to compare grammatical patterns not only within one corpus, but also across different languages and datasets.
2The annotation was performed automatically with language-specific models (see Erjavec et al., 2023 for detailed specifications). While these models were selected for their accuracy, users will still encounter errors in the annotations. This should not be seen as a discouragement from making use of the annotations, as even with some noise, they greatly enhance the possibilities for analysis and allow research questions that would be difficult or impossible to address by looking at raw text alone.
3Linguistic annotations are particularly important because they allow researchers to move beyond raw text and systematically explore patterns of language use in parliamentary debates, for example they can trace how political actors and social groups are framed grammatically by looking into the representation of the referents as subjects and grammatical objects, which in turn sheds light on how responsibility and power are distributed in discourse, or they can use grammatical information to study evaluative adjectives applied to different social and political groups revealing the attitudes towards those individuals., etc.
4Moreover, by exploiting linguistic annotation in queries, researchers can speed up the research process and avoid overlooking relevant material, e.g., searching by base forms instead of enumerating all possible word forms which can quickly lead to errors and missing entries, especially in morphologically rich languages. Annotations also make it possible to move beyond a predetermined set of keywords or phrases, opening the way for more explorative analyses, e.g., instead of only checking whether a specific term or phrase appears, researchers can examine how different grammatical constructions (mimicking the desired phrase) are distributed across the debates. In this way,linguistic annotations not only improve the precision and recall in corpus queries, but also expand the range of possible research questions beyond purely linguistic concerns, enabling scholars to investigate language use in order to reveal broader issues like political framing, identity construction, ideological positioning and the circulation of narratives.
Linguistic elements and lemmatisation
1In Figure 13, we see the list and frequencies of the elements ascribed during linguistic annotation.13 The numbers in this box refer to unique occurrences of a given element. This is illustrated well in the first line where we can observe that there are only around 320 thousand unique wordforms used in ParlaMint-PL, but all repetitions of the different word forms amount to the previously mentioned 35 million reported in the box represented in Figure 11 above. In fact, the full (non-repetitive) vocabulary used in ParlaMint-PL is actually smaller than the 320 thousand words just mentioned, since the lemma element tells us that there are only around 90 thousand unique units used in the corpus.
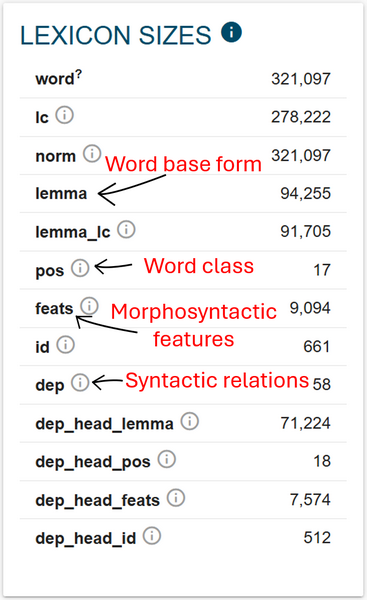
2A lemma refers to the canonical (dictionary) form of a word within a particular word class (part of speech) and, therefore, groups together all the different inflected forms of that word, disregarding their morphological variants used in different grammatical situations.14 Figure 14 shows the difference between wordforms and lemmas on the example of the verb głosować (to vote) from ParlaMint-PL.
Lowercase version
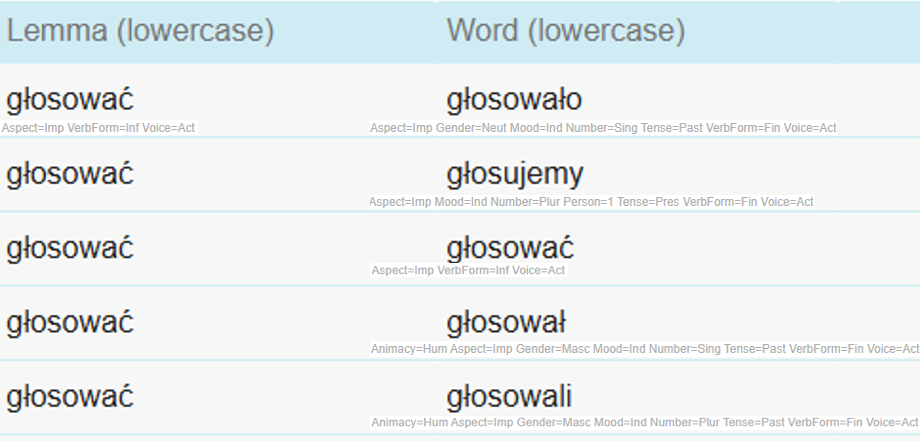
1To optimise corpus querying, corpora often include a lowercased version of the textual content. This means that all words which are otherwise written in uppercase letters, are given a lowercase equivalent. This facilitates more consistent searches, as users do not need to worry about differences in capitalisation (e.g., the Polish lower house Sejm vs. sejm), and ensures that case variation does not cause relevant results to be missed and at the same time avoid non-informative repetitions in word frequency lists. In Figure 13 above we can see two elements that refer to lowercased versions, namely lc which stands for lowercase word and lemma_lc which stands for lowercase lemma. Figure 15 provides an example sentence with annotations which show how the name Andrzej (the original word) is lemmatised as Andrzej, while the lowercased word and lemma equivalents are both andrzej. Note that the upper-case letters used at the beginning of sentences are often, although not necessarily, lowercased by default during lemmatisation, i.e. the process of ascribing lemmas to words, which is why both the lemma and the lowercased lemma of the original word Głos is głos. 15

Grammatical annotations
1Grammatical characteristics are encoded in ParlaMint on three levels. The box on the right in Figure 13 above encodes them as pos which stands for part-of-speech, feats which stands for morphosyntactic features and dep which stands for syntactic dependencies/relations. The frequencies given for a particular element refer to different forms of pos/feats/dep that appear in the corpus. As mentioned earlier, the grammatical information encoded in these elements can be useful in queries since they allow the researcher to search by a particular characteristic of a word/phrase rather than a list of actual words/phrases, and therefore to obtain more comprehensible results. However, apart from the pos categories which are only few and generally well known, e.g., verb, noun, adjective, adverb …, feats and dep values are much more numerous making it practically impossible to easily memorise all different characteristics that they encode. For this reason, it is best to always refer to the documentation of the tagset that was used in order to interpret or find a specific label.
2Corpus compilers may adopt different specifications/tagsets for linguistic annotation, and it is important for users to know which one was applied to correctly interpret the annotations and construct effective queries. The same linguistic feature can be referred to by different labels across frameworks, and these labels are exactly what queries operate on. In the case of ParlaMint, the compilers chose the Universal Dependencies (UD) formalism as the basis for annotation. The link to the tagset is provided also on the corpus information page in noSketch Engine. Figure 16 shows an example from ParlaMint-PL showing the three levels of annotations. In the first line, the subscripted labels indicate parts of speech (pos) such as NOUN and VERB, in the second line they mark morphosyntactic features (feats) such as Animacy=Inanimate, Case=Nominative, Gender=Masculine, Number=Singular, and in the third line they show syntactic relations (dep) such as nominal subject, object, root (referring to the main predicate here), and punctuation.

3➽ noSketch Engine tip: to display different levels of annotations, select the eye symbol (Figure 17) after you perform a search through the Concordance function (see Showcase II) or display the speeches/utterances through Text Type analysis (see Section Metadata).
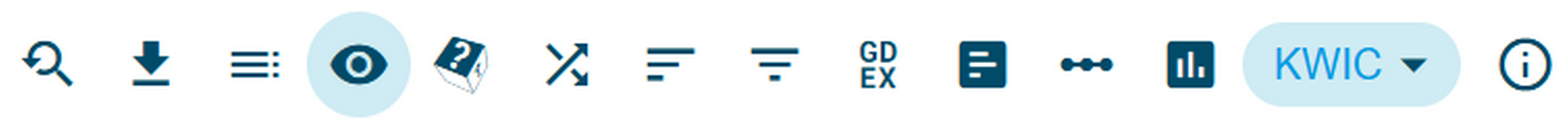
Metadata
1The third layer of information can be considered metadata which adds another crucial level by describing the broader contextual properties of the texts. This information not only helps contextualise the results, but it can be used, similar to linguistic annotations, in queries to limit the context of the search task. The metadata in ParlaMint was drawn from diverse sources, e.g., official records, expert surveys and ParlaMint-specific expert annotations, and in some cases produced automatically with machine-learning algorithms which were trained and evaluated on manual expert annotations (the procedures are explained at relevant sections below). The potential errors in metadata, linked either to processing issues or source data inconsistencies, are regularly corrected, which is why it is important to always use the latest version of the corpus.16
Overview of metadata in noSketch Engine
1As with structural markup and linguistic annotations, noSketch Engine corpus information page provides a useful overview also in the case of metadata categories. Figure 18 shows the Text Type box of the ParlaMint-BE corpus information page in noSketch Engine which groups metadata categories according to the structural level at which they were assigned.
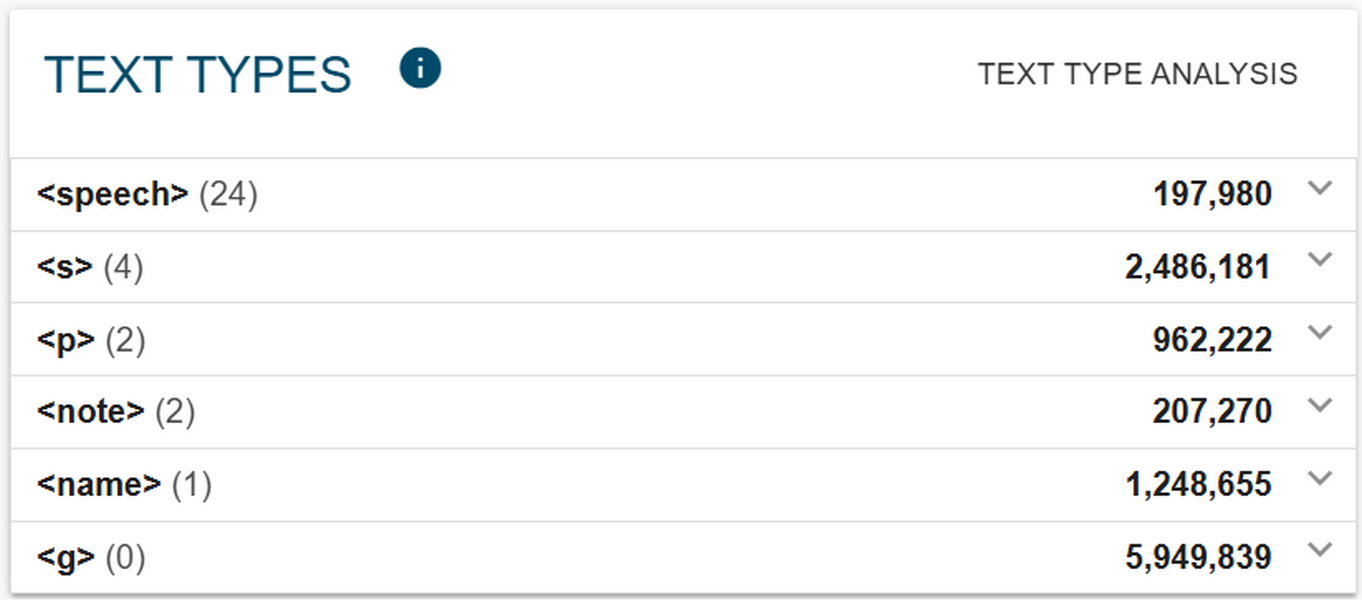
Sociodemographic and temporal information
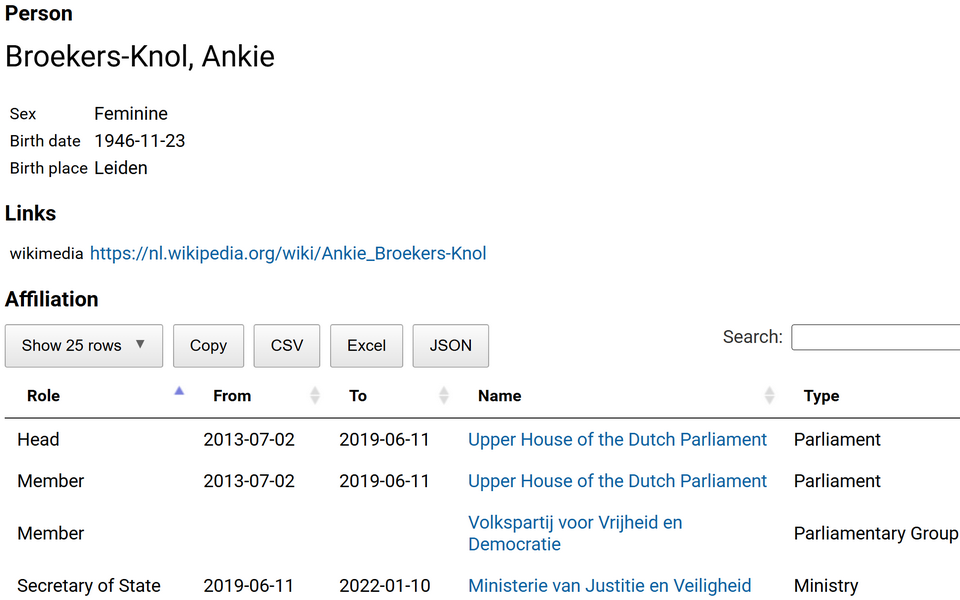
1The speech level is the most numerous in terms of text type categories. It groups metadata on speakers and speeches as shown by a coarse division into red and blue boxes (for visualisation purposes only) in Figure 19. All speakers are assigned a unique ID and described with a set of sociodemographic characteristics, such as birth year, gender, and name,as well as certain professional characteristics. The latter include their status as MPs or ministers, their role in the debates (either as chairpersons or regular speakers), and their affiliation with a political party. Erjavec et al. (2025) note that official records and external sources like Wikipedia and alike were used to gather this type of information.
2Speeches are assigned unique IDs along with temporal information encoded in speech date, speech title, meeting title, session, sitting, and term (see Table 1 in The ParlaMint corpora for a temporal overview of the data included). Whether all of these categories are available depends on the organisation of parliamentary work and on national parliamentary traditions. For example, in ParlaMint-BE the proceedings are not structured according to sittings, which is why this information could not be included in the corpus. By contrast, in ParlaMint-PL the official records provide details about sittings, so this information could be added to the data. Moreover, speeches are also annotated with the languages identified in the transcripts. As expected, in most countries speeches are delivered in a single language, but in parliaments such as Belgium’s, proceedings may take place in more than one language. While some transcripts also contain agenda titles, these were not included in the noSketch Engine interface.
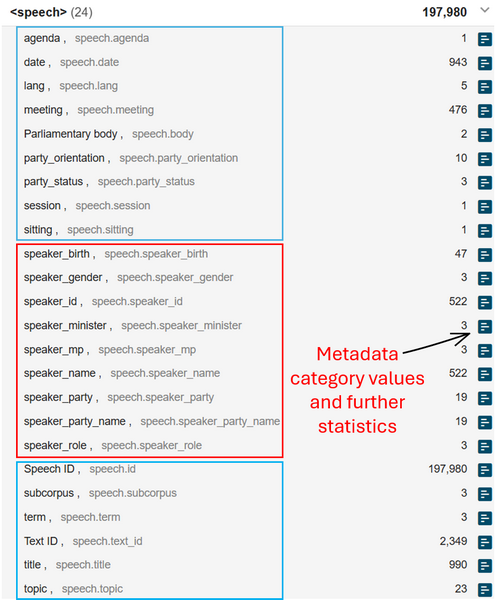
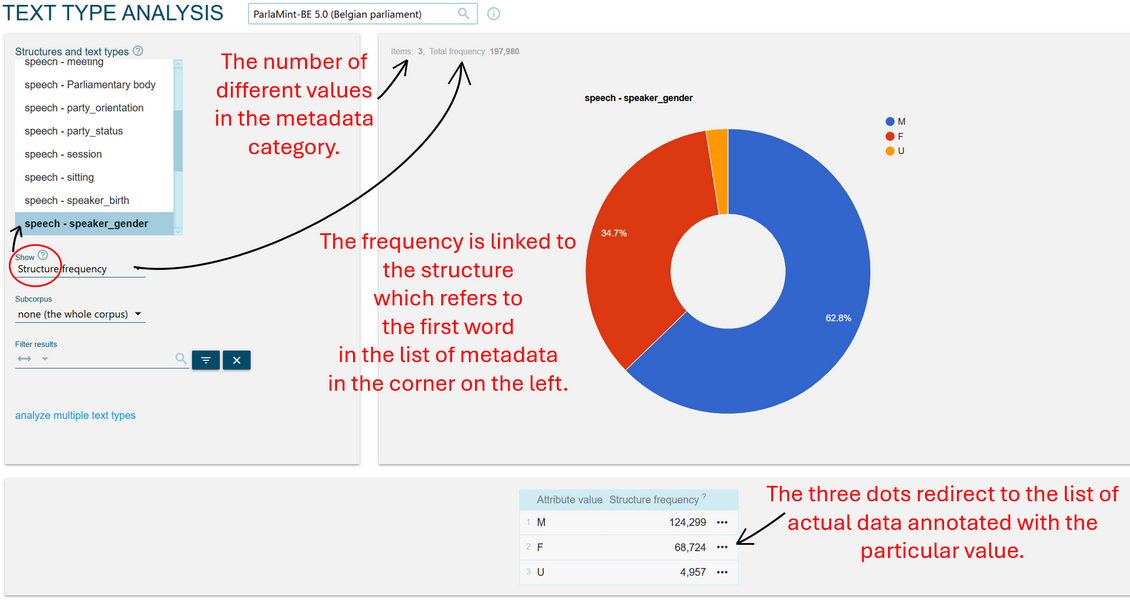
3➽ noSketch Engine tip: check the detailed statistics on sociodemographic information for ParlaMint-BE by going to this link and selecting the blue square with white stripes on the right side of the Text Types box beside the category of your choice (see the arrow in Figure 19).
4➽ noSketch Engine tip: understand and explore the detailed statistics. Figure 20 shows the distribution of MPs per gender in ParlaMint-BE according to the number of their speeches. By changing the option Show: Structure frequency right below the list of metadata categories, it is also possible to obtain the frequencies of tokens produced by gender. If you wish to get frequency information for groups defined by several parameters, e.g. by gender and party simultaneously, use the option analyse multiple text types written in blue on the left side of the screen. To check the speeches/utterances tagged with one of the metadata categories, e.g. only speeches by women (F), click the three dots next to frequency information at the bottom of the page.
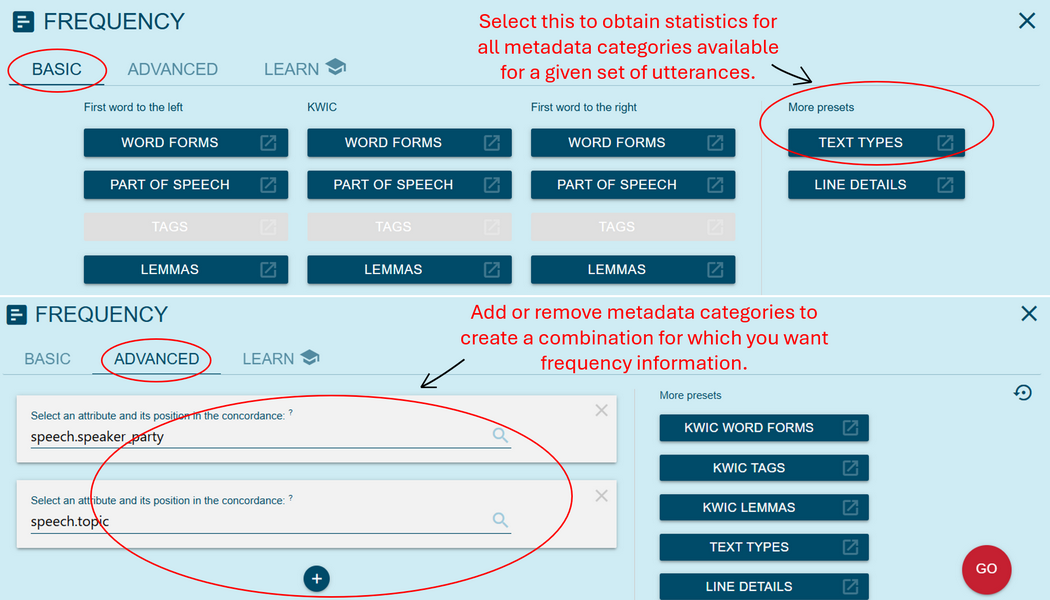
5➽ noSketch Engine tip: once we display the concordance lines for a particular value (see the previous point), we can explore further the statistics for that set of data. To do this, the frequency button (blue square with white stripes, as in Figure 21) at the top of the page should be selected. From there, we have two options (Figure 22): we can either select the preset Text Types to show the statistics for all different metadata categories available for the selected subset of data, or we can define a list of one or multiple metadata categories at the Advanced tab which produces the statistics for a combination of metadata categories.

6➽ noSketch Engine tip: for advanced users, the noSketech Engine corpus information page is highly useful also as a cheat sheet in formulating complex queries with metadata parameters. Complex queries use a specific syntax, or Corpus Query Language (CQL), which requires the user wishing to include some metadata-based conditions into the query to specify the structure, the metadata category and the desired value in the format <structure category =”value”/>. To understand how to properly fill in the placeholders, the user can check the corpus information page to find out how the different levels are named. For example, to search for all speeches produced by women speakers on the topic of Culture (in ParlaMint-BE), the query would be: <speech speaker_gender="F" & topic="Cultuur"/>. On the corpus information page, the correct naming for the structure, metadata category and its values are provided in light grey and via the blue square box with white stripes. Note that the dot between the structure and the metadata category is replaced by a space in the query. See Showcase II for some examples of CQL queries.
Political organisation metadata
1In ParlaMint, the user can also get information about the parliament body/bodies included in the corpus, parliamentary status of MP’s party and party orientation. A given ParlaMint corpus includes transcripts from the main parliamentary bodies of a country. For unicameral parliaments, this means the debates of the single chamber. For bicameral parliaments, the corpus usually includes debates from the lower house and the upper house, or only one of them, depending on data availability and national practice. (The Belgian corpus also includes data from parliamentary committees). Erjavec et al. (2025) state the following:
2“This is important information for the comparability of the corpora, as it is sensible to compare the speeches of the same type of body, although most likely treating unicameral parliaments and lower house as the same type. Most corpora are either unicameral or contain lower house transcriptions only, while Great Britain, Netherlands, and Poland contain transcripts of both the upper and lower house. The Norwegian corpus contains labels for both unicameral, as well as for lower and upper houses because in 2009 Norway changed its parliamentary system from a (pseudo-)bicameral to a unicameral one. The only corpus containing only the transcripts of the upper house is the Italian one. The Belgian corpus is currently the only one in ParlaMint that also includes the sessions of various parliamentary committees.”
3➽ noSketch Engine tip: check the detailed statistics on parliamentary bodies for all corpora combined here
4A speech is also attributed information on the parliamentary status of the party that the MP delivering the speech belongs to. When using this information, it is important to understand that only the coalition status was consistently annotated with time-stamped tags across the ParlaMint corpora. However, for a large set of countries, the opposition status of parties was also tagged. There is also the nonvalue (-) which indicates that the speech either does not belong to an MP affiliated with a party being in the coalition or opposition at the time of speech delivery, or no time-stamped data is available.
5➽ noSketch Engine tip: check this link to observe the detailed statistics for party parliamentary status for all corpora combined
6Political orientation of parties was added to the corpus based on data from Chapel Hill Expert Survey Europe (CHESS; Jolly et al., 2022), Wikipedia and in some very infrequent cases, the knowledge of the corpus compilers. In the paper Meden et al. (2023), where you can find a more thorough description of the encoding process for political orientation, authors state that while the CHESS database was recognised as a highly valuable resource for this task, its main drawbacks for the use with ParlaMint data are (1) that it does not cover all ParlaMint countries, (2) the data is available only up to 2019, while ParlaMint data goes far beyond that point in time, and (3) not all parties included in ParlaMint are represented in the CHES database. For this reason, it was decided to add data from Wikipedia pages (and in very rare cases, also annotations produced by corpus compilers) as the second layer of the annotation of political orientation. Since the CHES database contains numerical representations of political orientation and there was no objective way to pair those with the categorial values used in Wikipedia, it was decided that only Wikipedia values will be represented in noSketch Engine.17 Their particularity lies in the fact that these are fixed values collected from Wikipedia in 2022 and therefore do not capture the potentially shifting political orientations of parties over time, as the CHES dataset does. Moreover, the fact that the values were collected in 2022 does not imply that they represent the parties’ orientations in that specific year (some parties had already been dissolved by then), but simply that the information was harvested at that time. For this kind of information, the user needs to consult the CHES values in the original corpus files retrievable from the CLARIN.SI repository page.
7➽ noSketch Engine tip: check this link to observe the detailed statistics for party orientation for all corpora combined
Integrated subcorpora
1ParlaMint comes with three prebuilt subcorpora which can be viewed at the level of text types in noSketch Engine. A subcorpus is a subset of data that was filtered out based on metadata and/or a search string containing particular words and linguistic tags. noSketch Engine deployment with log-in option, which is used in this digital textbook, allows to create user-defined subcorpora which is crucial in many analyses where the user is not interested in the entire corpus content but just a specific part of it. In addition to these user-defined subcorpora, ParlaMint offers three built-in subcorpora that divide the corpus into three periods and reflect the initial COVID-oriented focus of the ParlaMint project (see Section The ParlaMint project). The three subcorpora that can be found in all ParlaMint corpora are:
- Reference period covering all data before 30 January 2020, i.e. the pre-COVID period ending with the date of WHO announcing the Public Health Emergency of International Concern with regard to COVID-19 outbreak
- COVID period covering data from 31 January 2020 to 23 February 2022, ending on the day prior to Putin’s announcement of Russia’s full-scale invasion of Ukraine
- COVID/War covering data after 24 February 2024
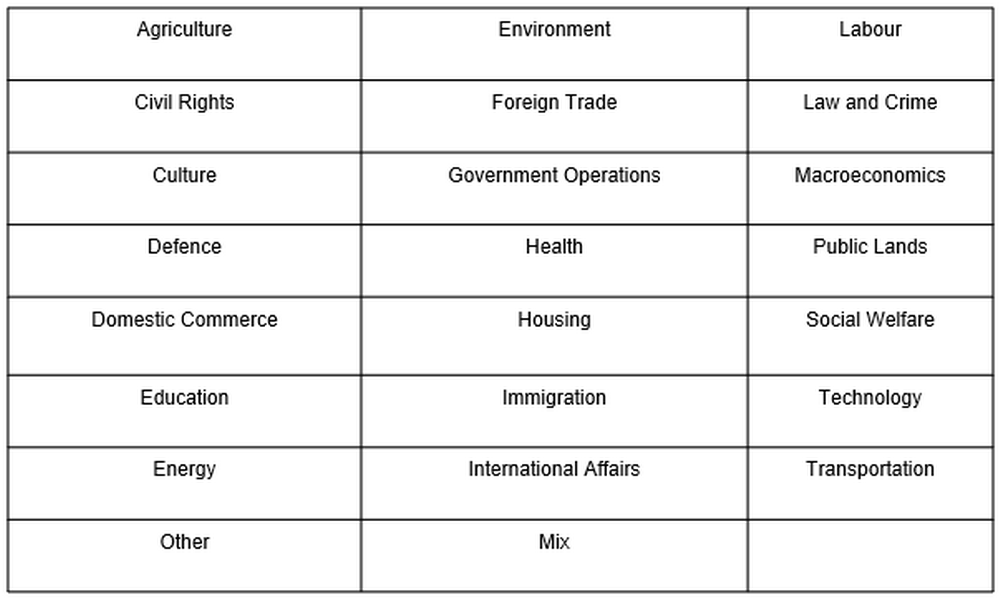
Topic information
1The metadata category capturing the speech topic is based on an automated annotation using a schema that comprises 21 categories from the Comparative Agendas Project (CAP) 18, which classifies policy-making activities, along with two additional categories: Other and Mix (see Figure 23). The definitions used for the 21 topics are available in the Appendix of Ljubešić et al. (n.a.). The label Other covers speeches that do not address a policy issue, for example, when speakers discuss meeting logistics, share personal stories, or engage in arguments, while the label Mix is applied to cases for which the prediction confidence score of the model was below 60%.
2The annotation procedure involved several steps. First, samples were extracted from each ParlaMint dataset to enable pre-training of the XLM-RoBERTa-large model on parliamentary discourse, resulting in the BERT-like model XLM-R-Parla. Next, automatic annotation was performed with a Generative Pretrained Transformer (GPT) model using a prompt and adapted CAP topic definitions (see the Appendix in Ljubešić et al., n.a.). Manual annotation of a test dataset was conducted to evaluate the model’s output, confirming that its annotations reached human-level quality (Kuzman & Ljubešić, 2025). To improve topic coverage, infrequent instances (e.g., for the Public Lands topic) were added to the training dataset, and the model was re-trained, leading to the improved version XLM-R-Parla-impr, published as the ParlaCAP-Topic-Classifier.
3➽ noSketch Engine tip: check this link to observe the detailed statistics of topic distribution for all corpora combined
Sentiment information
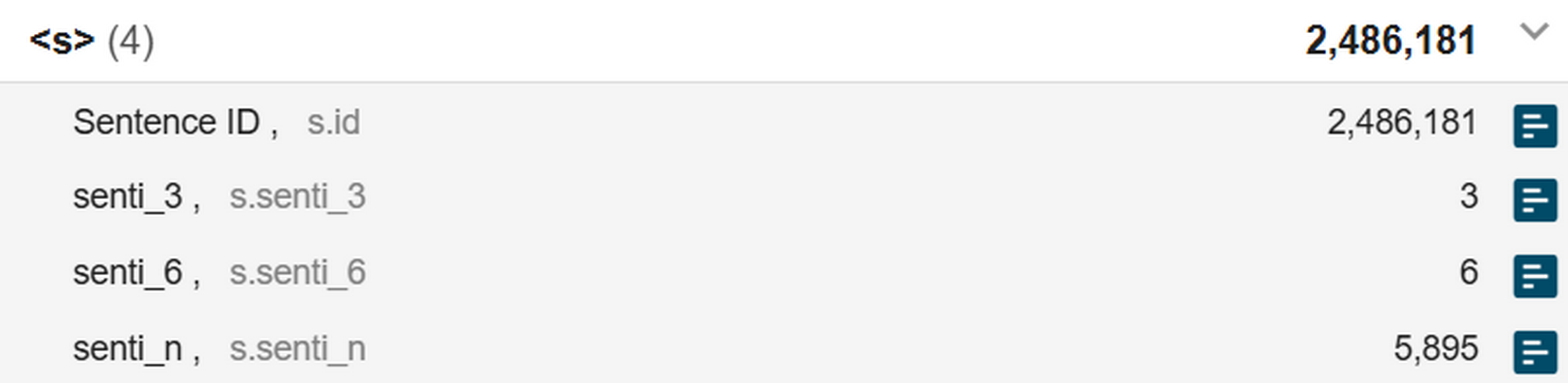
1Moving from the speech to the sentence level, the corpus provides metadata on sentence ID and sentiment (senti label), 19 provided on three different scales but reflecting a single annotation task (Figure 24):
- senti_6 gives information on 6 levels and follows the original schema (see Table 2)
- senti_3 gives information on 3 levels and simplifies the 6-level schema
- senti_n gives the numerical output of the model which returns an estimated sentiment score on a continuous scale20 which is then translated to the 6-level or 3-level scale
2The procedure involved the manual annotation of a training set using the six-level sentiment schema presented in Table 2. These annotations were then used to train the XLM-R-parla model, designed to predict sentiment scores on the same scale. XLM-R-parla is a domain-specific adaptation of XLM-RoBERTa-large, pretrained on parliamentary data. Building on this foundation, the ParlaSent model was developed, offering a deep learning approach to multilingual sentiment analysis within the parliamentary domain.
| LABEL (senti_6) | LABEL (senti_3) | DESCRIPTION |
| Negative | Negative | Entirely or predominantly negative |
| Mixed negative | Ambiguous sentiment or a mixture of sentiments, but leaning more towards the negative sentiment in a positive-negative classification | |
| Neutral positive | Neutral | Non-sentiment related statements, but still lean more towards the positive sentiment in a positive-negative classification |
| Neutral negative | Non-sentiment related statements, but still lean more towards the negative sentiment in a positive-negative classification | |
| Positive | Positive | Entirely or predominantly positive |
| Mixed positive | Ambiguous sentiment or a mixture of sentiments, but leaning more towards the positive sentiment in a positive-negative classification |
3To properly use and interpret the annotations, it is important to remember that in ParlaMint, sentiment is annotated at the sentence level, meaning that each sentence receives a label reflecting its overall polarity. The decision is based on the overall meaning of the sentence and the linguistic, rhetorical and typographical cues within the sentence itself, such as polarity markers (good, bad), intensifiers (enormous), diminutives, irony, metaphor, emoji, punctuation, etc. Importantly, context from surrounding sentences is not taken into account, so labels are assigned independently of the broader discourse.
4For this reason, the interpretation of sentiment labels should be approached cautiously. A sentence-level label does not necessarily indicate the attitude toward the sentence referents (since multiple entities may appear in the same sentence), nor does it capture the overall sentiment of an entire speech or debate (see also Showcase I and Showcase II). This is particularly relevant when formulating research questions about political attitudes, where more targeted methods looking only at the argumentation pertaining to a particular subject are necessary.
5Nevertheless, sentiment annotation remains useful for other kinds of analysis. It can help trace broad shifts in tone over time, compare variation in rhetorical style across speakers or parties, or examine whether certain policy areas are typically framed in more positive or negative terms. In this sense, sentiment tagging as realised in ParlaMint is often more informative about how things are said, e.g. emotionally charged vs. neutral style, than about what specific stance is taken toward an issue.
6➽ noSketch Engine tip: check the following links to observe the detailed statistics at 3-level scale / 6-level scale / n-level scale 21 for all corpora combined.
Transcriber notes
1The formal transcripts often include transcriber notes which include anything from voting results or timing and procedural information to information about different vocalisations in the room, like applause or interruptions, or remarks about inaudibility of the speaker, etc.
2Transcriber notes vary greatly between parliaments which is why there is, for the moment (ParlaMint 5.0, September 2025), no common categorisation proposed for this type of metadata. In ParlaMint (Figure 25), they are encoded as a separate structure that can be divided into up to two categories, namely type (the kind of action described) and content (a specification of that action), e.g., vocal:murmuring:Murmures sur les bancs du groupe LR. When displaying the values for type (by clicking the blue square with white stripes), we see that the type can be further specified as incident (non-communicative phenomena like action), kinesic (non-vocalised communicative phenomena like applause) and vocal (non-lexical vocalised phenomena like murmuring). Although the three specific types of notes were proposed as common labels in ParlaMint, there was no harmonisation of transcribers notes conducted between the corpora, which means that each corpora needs to be examined separately to understand what the notes contain and how they can be useful for the analysis.

3➽ noSketch Engine tip: check this link to observe the detailed statistics of note type in ParlaMint-FR. Switch to note content at the bottom of the list on the left side to display the statistics for that category.
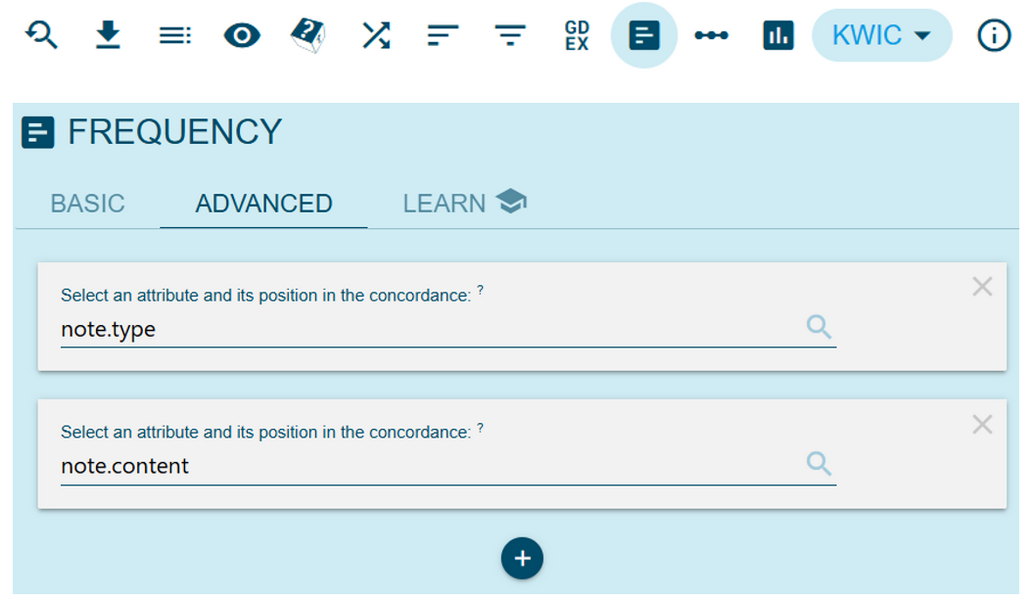
4➽ noSketch Engine tip: to observe note type and content together, we can first display the speeches containing the notes by clicking the three dots beside a selected note type from the ParlaMint-FR Text Type analysis page. Once we are redirected to the list of utterances/concordances, there are two options. We can observe the notes in context, by selecting the View options button at the top of the page and then enable note (under Show structures) and the option Show more context (Figure 26). It is also possible to list all different combinations of note type and content by clicking the Frequency analysis button at the top of the page, going to the Advanced tab (Figure 27) and defining two metadata categories of interest, note type (as the first one) and note content (as the second one).
Named entities
1Named entity recognition / annotation (NER) enables researchers to identify references to various unique (individual or collective) entities in the data and analyse, for example, potential networks, centres of special interest or power, cross-references between debates, etc. As shown in Figure 28, named entities are encoded in ParlaMint as a separate structure retaining one metadata category, i.e. type, with the four standard values (Tjong Kim Sang & De Meulder, 2003) – organisation (ORG), person (PER), location (LOC) and miscellaneous (MISC ) where the latter refers to any named entity that does not belong to any of the previous three classes, such as Dispatch Box, Nationality and Borders Act or Shakespearean/Wagnerian (examples taken from ParlaMint-GB).
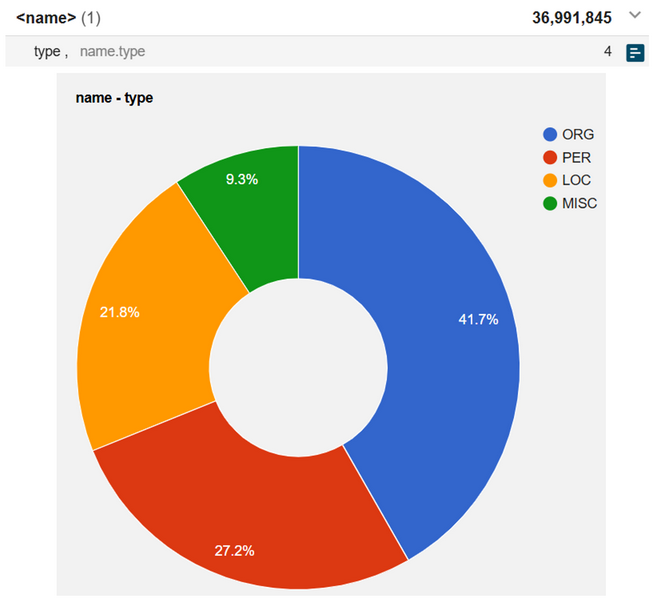
2➽ noSketch Engine tip: check this link to observe the detailed statistics of named entities distribution for all corpora combined
3➽ noSketch Engine tip: to list all different occurrences of a NER type, we need to produce a frequency list of these occurrences. One of the simple ways to do it, is to first go to the Text Types analysis page of the selected corpus (in this case, ParlaMint-AT) and click the three dots beside the selected NER value at the bottom of the page (for example, LOC). To obtain a non-repetitive list of all the locations in the data in focus, we click the Frequency analysis button and then, in the middle column under KWIC (Key Word In Context) select the option lemma (Figure 29). The same steps would be followed also if we want to observe only speeches with a more limited context and, therefore, we will first produce the concordance lines through the search option (Concordance) and then follow the steps just described. To display the annotations in context, use the View options button and check name under Show structures (see also Section Transcriber notes above).
Semantic annotation
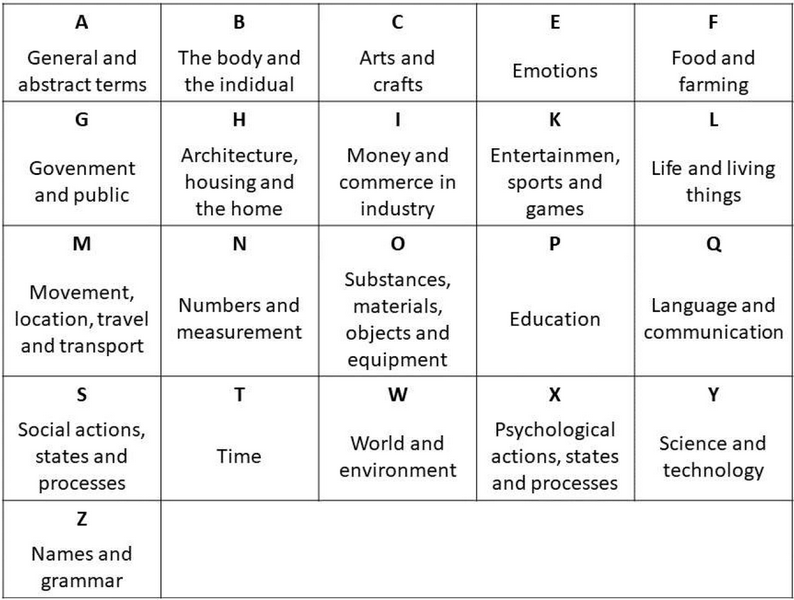
1The machine-translated version of ParlaMint into English (Kuzman et al., 2025) is annotated with semantic tags, meaning that each word in the translated corpora is assigneda label describing its domain of meaning. In ParlaMint, these domains are drawn from the UCREL Semantic Analysis System – USAS (Rayson et al., 2004) which is composed of a closed set of 21 major top-level categories with several subcategories (Figure 30). The system covers both single words and multiword expressions and includes methods for contextual disambiguation. These methods combine part-of-speech tagging (to narrow down which semantic tags are relevant), general likelihood ranking, and rule-based heuristics, all of which increase the chances that the correct tag is assigned to a word in context.
2In noSketch Engine, the English machine-translated version of the corpus is called ParlaMint-xx-en and includes semantic annotations on a separate structural level under three metadata categories (Figure 31):
- USAS categories 22: the numerical values that correspond to the entries in the USAS tagset23 as specified in ParlaMint USAS taxonomy, e.g., Q4.3;
- USAS glosses: the numerical values together with their gloss/category name, e.g., Q4.3: The Media: TV, Radio and Cinema;
- USAS tags: the original output of the automatic annotation.
3USAS categories and glosses indicate the tag which was computationally determined as the most appropriate for a word or multi-word expression in a given context. USAS tag, on the other hand, shows all lexically possible tags for a given unit mapped directly from the USAS lexicon containing words and multi-word expressions with corresponding tags. When a unit was assigned several tags, e.g., parents: S4mf,A9+, the first tag (S4) was considered contextually the most suitable one (and encoded at the level of USAS categories/glosses).

4In interpreting semantic annotation in ParlaMint, it is important to keep in mind that the annotations are performed based on a lexicon of single words and multi-word expressions24 that are labelled with appropriate semantic tags. The tagger matches the entries from the corpus with those in the lexicon and maps the corresponding semantic tags. The user might come across the following situations (Figure 32):
- when a unit is recognised as a multi-word expression (because it was defined as such in the lexicon), all its constituent parts are given the same, possibly compound tag, e.g., world war two where the constituent parts are interpreted as geographical names (Z2) or many years, tagged as P1 S2, where each part of the multi-word expression is given the tags of both parts (many: P1 + years: S2);
- when a unit is a single word or not recognised as a multi-word expression (even when effectively pointing to the same referent but not in a format recorded in the lexicon), each unit is given its own tag, e.g., the second world war which was tagged with the domains grammatical bin (Z5), linear order (N4), universe (W1) and warfare, defence and the army; weapons (G3);
- whenever there are several possibilities for a given unit, the first one is selected as the most appropriate one at the level of USAS categories/glosses, e.g., war which is tagged as G3,S7.3 in the initial output (USAS tag) keeps only tag G3 at the level of USAS categories/glosses.
5Please note that semantic tagging is a highly complex computational task, and even human annotators often differ in their judgments about the most appropriate semantic tag for a given word. For this reason, users are expected to familiarise themselves with the underlying taxonomy, i.e., set of possible categories, and adopt a flexible approach when interpreting the labels. Semantic tags are best understood as tools for gaining an initial overview of the data and identifying relevant samples for qualitative analysis, rather than as definitive annotations in their own right.

6Semantic tagging can be used to identify patterns in meaning across large corpora. However, as mentioned in an earlier section, ParlaMint also includes topic annotations (see Section Topic information), which can be considered another form of semantic annotation. To make best use of both layers, it is good to consider the following:
- Semantic annotations are only available for the machine-translated English version of ParlaMint, while topic annotations are provided for all ParlaMint corpora (both for corpora in the original language and for their translated versions).
- Semantic tagging is applied at the word level and could thus be considered actually part of the linguistic annotation layer, whereas topic annotation is applied at the speech level.
- The two annotation layers differ in their schemas. Semantic tagging relies on the USAS taxonomy, which comprises 21 broad domains of human experience and knowledge (Figure 30), while topic annotation is based on the Comparative Agendas Project (CAP) schema, which is specifically designed to classify policy agendas and parliamentary topics (Figure 23).
- Although both annotations are automatic and rely on manually created knowledge, they use different generations of computational models. Semantic tagging is performed with pymusas (Python Multilingual UCREL Semantic Analysis System), a rule-based tagger that combines lexicon lookups with spaCy components for tokenisation and handling of multiword expressions. Topic annotation, on the other hand, is performed with a large multilingual transformer model. Specifically, it uses the XLM-R-Parla model, a BERT-like model that has been additionally pre-trained on parliamentary proceedings. The speeches were then automatically classified into CAP categories using the GPT-4o model (see Section Topic information).
7Semantic tagging is sometimes used to extract the topics of speeches, but given the schema used in ParlaMint, this is not the most efficient application of this annotation layer – especially since a dedicated topic-annotation layer already exists for the corpus. Instead, the two layers should be seen as complementary. Semantic tagging provides a bottom-up perspective on how words are used (tags are assigned at the word level), making it particularly valuable for linguistic and discourse analysis. By contrast, topic annotation offers a top-down perspective on what debates are about (tags are assigned at the speech level), which is more suitable for political science research and related fields.
8Together, they enable researchers to study not only what parliaments talk about, but also how they talk about it. For instance, semantic annotations can be used to analyse the use of emotional language across debates or to track how economic vocabulary is distributed over time and across the topics identified by the topic-annotation layer. This, in turn, allows us to understand how much parliamentary attention is devoted to areas such as healthcare or infrastructure, for example. Semantic tags also make it possible to compare rhetorical styles, e.g., whether debates rely more on emotional or technical vocabulary, to measure shifts in framing, e.g., whether migration is discussed in terms of economy or security, and to conduct cross-national comparisons, e.g., whether different parliaments emphasise similar or different semantic domains when addressing the same policy issue.
9➽ noSketch Engine tip: check this link to observe the detailed statistics for semantic domains for the English machine-translated version of ParlaMint corpora
Some considerations
1The Section on Corpus provenance, structure and annotation provided an overview of the rich annotations included in ParlaMint. We saw the diversity of information layered on top of the original transcripts, and the comparability not only of the underlying data but also of the added annotation layers. It is crucial to understand that data annotation produces more than just descriptive labels. Instead, they are powerful research tools that allow scholars to delimit searches, contextualise results, and refine analyses in ways that directly shape findings. For example, excluding chairpersons may be essential when investigating the framing of topical issues, since their contributions often concern procedural matters; if the metadata identifying chairpersons are absent, such a filter becomes impossible and the results risk being skewed. All of this greatly extends the value of ParlaMint as a data resource suitable for a wide range of research questions – both within a single parliament and for comparative work. However, when working with any part of the corpus – whether original transcripts, translations, metadata, or linguistic annotations – several considerations need to be kept in mind. Issues specific to the original texts have already been discussed in Section Working with Parliamentary Corpora; the following paragraphs focus instead on considerations related to machine translations and annotations.
2When using the machine-translated versions of ParlaMint, researchers should be aware that these texts are designed primarily to enable comparability across corpora rather than to provide perfect linguistic fidelity. Machine translation may smooth over idiomatic expressions, rhetorical nuance, or culturally specific references, which can affect analyses that depend on fine-grained linguistic detail (for some examples see Erjavec et al.). Semantic annotations are only available for the translated corpora, which makes them valuable but also means that any potential translation errors can propagate into the annotation layer. It is therefore important that researchers explicitly acknowledge the use of machine-translated data in their analyses and, where appropriate, cross-check findings against the original texts, which are easily accessible in noSketch Engine (see Section Analysing the keywords on health). In this way, the translations are most reliable for large-scale, comparative analyses of meaning, but should be used with caution in studies requiring close linguistic or stylistic interpretation.
3Regarding the metadata, despite extensive efforts to produce comparable corpora, limitations in available data and national political traditions mean that some metadata fields may be systematically missing or inconsistently populated – for instance, the birth-year field is empty in ParlaMint-GB, but not in ParlaMint-SI. It is therefore essential to check each corpus you plan to use before you finalise your study plan: what is present, what is missing, and how evenly fields are populated.
4Moreover, any annotation campaign requires decisions about logistical setup (e.g., number of annotators, annotations per item, annotator training) and the annotation schema. The schema substantially influences outcomes and the usefulness of the annotations for different user communities. No taxonomy will be ideal for all research questions. By understanding both the procedure and the schema used, it becomes easier to leverage the considerable work already invested in annotation and to find ways to reuse or adapt the data for one’s purposes.
5In ParlaMint, metadata categories follow shared taxonomies designed to reflect available source data and ensure comparability across corpora – one of the collection’s main advantages. This does not mean they should be accepted uncritically or applied uniformly across studies, nor discarded at the first sign of mismatch with the framework the researcher has in mind. For some projects, categories, used in ParlaMint, may be too broad to capture important distinctions, for others, too narrow. In such cases, it is advisable to treat the annotations as a starting point: to help filter the data, to be used for triangulation with other annotations, to reinterpret them in light of a selected analytical framework. It is always possible to set them aside altogether and focus just on the original texts. A case in point are political orientation metadata: the broad categories used in ParlaMint may not capture the nuances required for fine-grained studies of the far right in political science, yet they remain valuable for more broadly designed analyses of party landscape or as the first data filter. The key is to approach metadata critically and reflexively, in connection with the adopted research questions and theoretical assumptions.
6Finally, it is important to understand how the metadata and annotations were produced. Sociodemographic information in ParlaMint was typically drawn from official parliamentary records and can generally be trusted, aside from occasional clerical errors. In other cases, such as political orientation, expert sources or triangulated records were used to fill gaps. In other cases, automatic models trained and/or evaluated on expert annotations, such as those used for sentiment and topic annotation, were applied to generate high-confidence predictions.Each of these methods carries implications for reliability and for the kinds of questions that can be answered with the available tags. Inevitably, some errors persist, whether due to inaccuracies in source data, misclassifications by predictive models, or processing issues. Although multiple mitigation measures were implemented in ParlaMint, like systematic error checking and the use of high-accuracy models, no dataset is error-free, but rather than dismissing the metadata, researchers should just approach them with due vigilance and try making the most out of the data.
7In addition to these corpus‑level considerations, it is also important to recognise the inherent limitations of the traditional corpus analytical methods available in noSketch Engine and TEITOK. Measures such as keyword lists, collocations or frequency comparisons can be highly informative, yet they are sensitive to factors such as reference corpus choice, tokenisation differences, and the statistical thresholds applied. Keywords, in particular, are only indicators of potential salience and may be misleading without close contextual reading. Similarly, collocates can foreground patterns that reflect methodological choices – such as window size or association measures – rather than underlying linguistic behaviour. These methods therefore work best when combined with careful interpretation, iterative checking, and an awareness of how tool settings shape the results.
1. ParlaMint-BE also contains proceedings of parliamentary committees. ParlaMint-IT only contains proceedings of the upper chamber.
2. The majority covers national parliaments, but ParlaMint includes also the proceedings of three regional parliaments of the Catalan, Basque and Galician autonomous regions.
3. Data retrieved from Inter-Parliamentary Union: https://www.ipu.org/ on 22 August 2025.
4. noSketch Engine is a non-commercial version of Sketch Engine developed by Lexical Computing. Although one of the early versions of ParlaMint is available through Sketch Engine, we recommend using the CLARIN.SI installation of noSketch Engine which offers the latest version of the corpora.
5. “Machine translation was performed with the pre-trained Transformer-based OPUS-MT models. /…/ Overall, the machine translation output was found to be of high quality, however, approximately 20–30 % of the sentences still contained common machine translation errors. The errors can be on the word level, such as very frequent incorrect translations of proper nouns (e.g., The Winner of the Welcomes instead of Zmago Jelinčič Plemeniti, the name of a Slovenian politician) or incorrect translation of terms (e.g., State Assembly instead of National Assembly). Errors can also occur at the level of multi-word expressions (e.g., literal translation of Besedo dajem to I give my word to instead of I give the floor to), or at the utterance level, where we observed repetitions, additions, and hallucinations, that is, MT output that is not related to the source text. Therefore, it is crucial for any studies using translated corpora to clearly outline the limitations of using machine-translated content and to cross-check the findings with the source texts.” (Erjavec et al., 2025, p.2088–2089)
6. To follow a tutorial on using this tool, refer to https://sidih.si/20.500.12325/2177 (Pretnar Žagar et al., 2022).
7. Note that at the time of writing TEITOK supports version 4.1, while 5.0 has not yet been loaded.
8. See Section From noSketch Engine to TEITOK below to learn one of the easy ways to visualise a section of the debate, found in noSketch Engine, in TEITOK.
9. While this is generally true, the user should pay attention to the corpus version used in noSketch Engine and TEITOK, since it is possible that new versions of corpora are not included on both platforms simultaneously.
10. The scope of provided detail may vary between individual ParlaMint subcorpora.
11. See Figure 5. Click Corpus search and query builder from the menu on the left side of the screen or from the description page of the corpus.
12. Note that noSketch Engine and TEITOK use ParlaMint data in vertical format (available also in the repository) which differs from the full TEI format in certain aspects. For example, it reduces certain metadata information, like the one on political orientation, to make the data suitable for use in the concordancers. The vertical format is also less extensively documented, so in some cases it may be useful to consult the detailed description of the corpus encoding available at this link (Erjavec, Kopp & Pančur, 2025).
13. Although the annotation of named entities, like persons, organisations and places, which is included in ParlaMint, is usually considered part of linguistic annotation, we follow the distribution of categories proposed in noSketch Engine for ease of presentation. Therefore, named entities will be presented in Section Metadata.
14. Note that contracted forms are lemmatised separately. For example, du peuple français is annotated as de|le peuple français; whether it's the NHS is annotated as whether it be the nhs; his party's leadership is annotated as his party 's leadership.
15. This depends on the rules defined in the lemmatiser, i.e., the tools that perform lemmatisation. Either way, the rule is then applied consistently across the corpus (some errors are, however, always possible).
16. Previous versions are listed in the CLARIN.SI repository and available through noSketch Engine, but for most up-to-date data, it is best to always choose the latest version.
17. For the moment (September 2025), noSketch Engine exhibits some speeches being labelled with multiple values (see here, for example, the label Centre;Centre-right). Such speeches belong to speakers who themselves are tagged as belonging to multiple parties (e.g., Tomenko, Mykola Volodymyrovyč – Batkivshchyna;BPP). This is linked either to data processing errors or to 1-day overlaps between parties when the person switched their affiliation.
18. Comparative Agendas Project Master Codebook: https://www.comparativeagendas.net/pages/master-codebook
19. At the time of writing, sentiment information is also available at the speech level for ParlaMint-SI 5.0, while for other ParlaMint corpora this layer may be added in future releases.
20. The scores translate to the 6-level schema as follows: <0.5 = negative / 0.5 to <1.5 = mixed negative / 1.5 to <2.5 = neutral negative / 2.5 to <3.5 = neutral positive / 3.5 to <4.5 = mixed positive / 4.5 or more = positive. The scores translate to the 3-level schema as follows: <1.5 = negative / 1.5 to <3.5 = neutral / 3.5 to <5 = positive. Note that senti_n may include scores below 0 and above 5, even though the training data – manually annotated – contained only discrete sentiment scores from 0 to 5. This occurs because the model predicts sentiment using a regression approach, which outputs values on a continuous scale and can therefore produce scores outside the original 0–5 range.
21. Note that in version 5.0 you may encounter cases where two sentences with the same value on the n-level scale are assigned different tags on the 3/6-level scale. This results from the rounding procedure applied during preprocessing and does not affect the validity of the assigned tags. For this reason, and for ease of use, the 3/6-level scale is recommended.
22. In the next ParlaMint update, i.e. in version 5.1, it is planned that USAS categories will be transformed to only reflect the top-level semantic domains, i.e. those indicated in Figure 30.
23. The two tagsets, USAS tagset and ParlaMint USAS taxonomy, are the same with the only difference being that the original tagset uses symbols +/- while the ParlaMint taxonomy translates these into p/n to facilitate their use in CQL queries which would otherwise necessitate escaping these characters.
24. In frequency lists of semantic tags, multi-value entries, e.g., P1/S2, indicate multi-word expressions. However, note that single entries can also refer to multi-word expressions, e.g., world war when both parts are tagged with Z2. On the other hand, when there are several possible tags for a given unit, these are delimited by a comma in noSketch Engine.