1Parliamentary corpora, which contain the records of parliamentary debates, provide an important source for researching politics and its impact on society. These corpora usually hold rich metadata on the speakers and speeches and include multi-layered linguistic annotations that enable researchers to explore various research questions. Due to the size of such corpora, text mining methods, such as topic modelling, which enables topic extraction, prove to be extremely useful in researching their content. In this tutorial, we present the LDA method, one of the most popular methods for topic modelling. The analysis based on this method is performed in Orange, an open-source software for visual programming, which allows advanced data processing without code. The analysis in this tutorial was made on the ParlaMint-GB corpus that contains British parliamentary records.
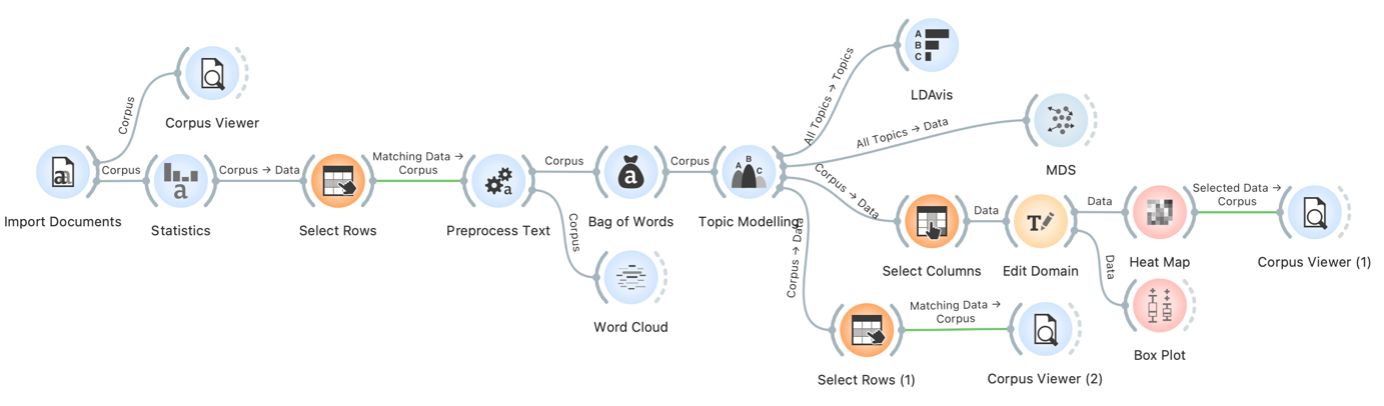
2The tutorial is designed for self-study and breaks down the analytical process into simple steps illustrated by numerous screenshots for easy progress (Figure 25). It also includes instructions for additional individual work, which helps consolidate the acquired knowledge and encourages users to use the software independently. While special emphasis is given to the presentation of the key characteristics of the analysed data, the tutorial also describes the specificities and limitations of the method used, thus promoting a critical approach to data analysis.
3Although the tutorial bases its analysis on the British parliamentary data, it is easy to extend the research to other text genres and other languages. Since the presented method is not language-specific, it can be used on any of the ParlaMint corpora. The value of the tutorial for students and researchers in the social sciences and humanities, therefore, reaches far beyond the specific research problems explored in this tutorial.