1To analyse parliamentary debates, we will use topic modelling, one of the text mining techniques used for researching large data sets. Given that several topic modelling methods exist, it is vital to know the advantages and disadvantages of each to choose the one that yields optimal results, which would provide quality results and ensure a critical interpretation of the results (Shadrova, 2021). In this chapter, we present the selected method of topic modelling and some examples of its application to parliamentary discourse.
2Topic modelling is a popular technique for automatic text analysis, which extracts the main topics in a corpus. A topic model assigns each document in the corpus to one or more topics. These topics are not actual text topics but rather sets of words that co-occur with high probability and hence form a single topic. The researcher must then manually define or name the topic described with these sets of words.
3Various methods (algorithms) can perform topic modelling on a corpus (Vayansky and Kumar, 2020). One of the most frequent ones is LDA or latent Dirichlet allocation, which we will use in our analysis. The method was developed by Pritchard et al. (2000) and adapted for text analysis by Blei, Ng, and Jordan (2003). The method is best suited for processing large textual data sets which cannot be analysed manually due to their size.
4.1. The LDA method
1The LDA method includes the following steps, performed in iteration:
- The algorithm first randomly allocates topics to the words in the corpus.
| document | word | |||
| epidemic | crisis | tax | economy | |
| doc1 | topic 1 | topic 2 | topic 2 | topic 1 |
| doc2 | topic 1 | topic 1 | topic 2 | topic 1 |
| doc3 | topic 2 | topic 1 | topic 1 | topic 2 |
| doc4 | topic 1 | topic 2 | topic 2 | topic 2 |
- Next, the algorithm counts the number of times a particular topic appears in each document (left table) and the number of times a certain topic is assigned to each word (right table).
|
|
- The algorithm then assumes it no longer knows the topic of a given word.
| epidemic | crisis | tax | economy | |
| doc1 | ? | topic 2 | topic 2 | topic 1 |
| doc2 | topic 1 | topic 1 | topic 2 | topic 1 |
| doc3 | topic 2 | topic 1 | topic 1 | topic 2 |
| doc4 | topic 1 | topic 2 | topic 2 | topic 2 |
- Then, it updates both tables from step 2 by once again computing the frequency of topics in the corpus (left table) and the frequency of words in the topics (right table).
|
|
- It computes the strength of the connection between a document and a topic (the probability of the topic in a document: the blue rectangle) and the connection between the topic and a given word (the probability of a word in a topic: the red rectangle).
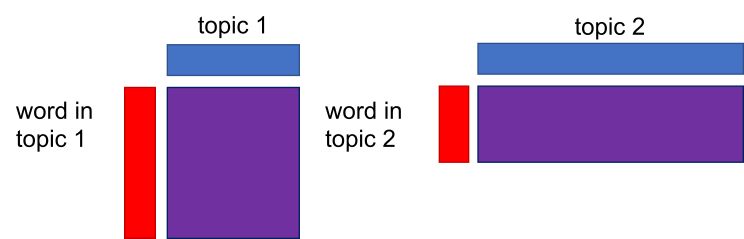
- The purple rectangle is a product of the red and the blue rectangle and represents the probability of a word in each topic. Based on the computed probability (purple rectangles), the method determines which topic will be assigned to a given document (green star which denotes a random allocation of the topic to the document, based on the computed word-topic probabilities).
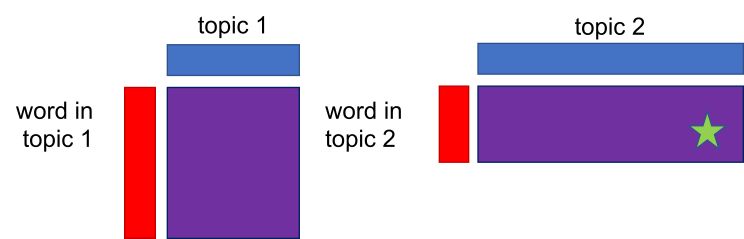
In short, the algorithm assigns a new topic (green star) based on the probability (purple rectangle). The probability distribution of topics in the document is based on the Dirichlet distribution, which postulates that the probability is never zero. Non-zero probability means that each word has at least a small chance of belonging to a less frequent topic and, concurrently, that even a lesser topic is present in a document. Once the topic is assigned to the word, the documents-words table is updated.
| epidemic | crisis | tax | economy | |
| doc1 | topic 2 | topic 2 | topic 2 | topic 1 |
| doc2 | topic 1 | topic 1 | topic 2 | topic 1 |
| doc3 | topic 2 | topic 1 | topic 1 | topic 2 |
| doc4 | topic 1 | topic 2 | topic 2 | topic 2 |
- Based on the new value from the table in step 6, the algorithm updates both tables: the topic-document and the word-topic table.
| topic 1 | topic 2 | |
| doc1 | 1 | 3 |
| doc2 | 3 | 1 |
| doc3 | 2 | 2 |
| doc4 | 1 | 3 |
| topic 1 | topic 2 | |
| epidemic | 2 | 2 |
| crisis | 2 | 2 |
| tax | 1 | 3 |
| economy | 2 | 2 |
- The procedure is repeated until the topic assignments stop changing. The result is a topic model. The topic is defined by a set of words which frequently co-occur in the text.
2Above, we have described the Gibbs sampling version of LDA. Please note that Orange uses variational inference instead of Gibbs sampling. Gibbs sampling is much more precise, while variational inference is faster for larger data sets.
4.2. Characteristics of the LDA method
1LDA is based on multiple assumptions. The first one is that the topic is defined by the words that frequently appear together. LDA is a language-independent method since it merges words into groups based on their occurrence in the text and not on their meaning. The same method can thus be used on corpora in different languages. At the same time, each word can be assigned to multiple topics; however, its probability in each topic will vary.
2The second assumption is that not all topics in the corpus appear equally often, and that they are unrelated. LDA does not define potential connections between the topics; however, it shows the probability distribution of topics in the text, which defines their importance in each document. Each document contains several topics, with one topic usually standing out (i.e., the document contains more words associated with the main topic compared to other topics).
3The third assumption is that the number of topics is predefined. The researcher must first set the number of topics into which the algorithm sorts the documents. The optimal number of topics for a given corpus is the one at which it is easiest to interpret viable topics for given sets of words that must be informative in terms of the research problem. Researchers, therefore, typically apply the topic modelling procedure several times for a given research problem, each time setting a different number of topics, and assessing the informativeness of the word sets that the algorithm extracted from the corpus. Some researchers also use additional statistical tests to adjudicate between results of models with different numbers of topics (Smith and Graham, 2019). Even though a suitable number of topics differs from case to case, the usual number ranges between 5 and 50 topics (Arun et al., 2010) and many papers go with 20 topics (Zhao et al., 2015; Gkoumas et al., 2018; Rosa et al., 2021).
4The fourth assumption is that word order in a corpus is not important. LDA works based on the so-called bag of words which does not consider the linguistic structure or specific connections between the words. This assumption is problematic because the word order is one of the key characteristics of language.
5The results are importantly affected by document order, as the method randomly assigns topics to documents at the beginning. If the document order changes, the initial assignments will also change. The temporal sequence (i.e., the timestamp) of the documents can also importantly affect the characteristics of the documents (Vayansky and Kumar, 2020).
4.3. Data preprocessing
1Before topic modelling, the data requires preparation which usually includes tokenisation (splitting the text into tokens, usually words, numbers, and punctuation), lemmatisation (assigning the base form to each token), and part-of-speech tagging (assigning the part of speech, e.g., verb, to each token). The procedure enables us to perform topic modelling on a single word form. Research has shown that lemmatisation and limiting the tokens to nouns improve the algorithm's speed and results. The improvement shows in the coherence or the sensible relations between word sets, based on which it is easier to assign a topic (Martin and Johnson, 2015). Differentiating by part-of-speech tags can also be used for answering different research questions. Van der Zwaan et al. (2016) performed topic modelling on nouns to retrieve topics. They then ran the algorithm on verbs, adjectives, and adverbs and used the results to elicit the positions of the MPs. Before using LDA, we usually remove overly common words from the corpus: words that can be too general (e.g., pronouns, prepositions) or too specific for the genre (e.g., words of address, such as esteemed in the parliamentary corpus). Depending on the research problem, very rare words, punctuation, capital letters, etc. can also be removed (Smith and Graham, 2019)
4.4. Limitations of LDA
1One of the limitations of LDA is that the method requires long texts for good results as it is based on word distributions, which are spurious in shorter texts. LDA is thus not appropriate for topic modelling of tweets, user reviews, or poetry. Even though it could be used to analyse, for example, Facebook posts (see Serrano et al., 2019), it is recommended to use other topic modelling methods for such tasks (Albalawi et al., 2020; Morstatter et al., 2018). Parliamentary speeches are usually long enough to achieve good results with LDA. However, certain speeches can be very short, and it is wise to remove them before running the analysis (Chapter 5.4).
2Another limitation is the assumption that words, just like the documents and the topics, are not co-dependent, which is linguistically imprecise on the one hand and does not allow for an analysis of correlations between words or between documents on the other. LDA suffices since these correlations are not the focal point for many research problems. However, if correlation is important (e.g., if we are interested in topic progression over time), there are more suitable methods, such as dynamic topic modelling (Müller-Hansen et al., 2021).
3LDA will also underperform if the text does not address the topic coherently but touches upon the topic with a few words only. On the other hand, the method works extremely well for longer, thematically well-defined texts, such as news, academic papers, political speeches, and certain literary genres.
4The next limitation is related to the number of topics the researcher has to define autonomously and is usually the result of trial and error. Allen and Murdock (2020) warn about overly specific topics representing only small sections of the text when the number of requested topics is high, making it difficult to establish thematic relations between texts. Conversely, when the number of topics is very limited, they will frequently be too general and thus uninformative to the research.
5As a final limitation, we can mention the difficulty of interpreting topic modelling results, including how the results are published. As the result of topic modelling are individual sets of words, there is a danger that the researcher will recognize a pattern in them even when none is present, meaning they will identify the topics they had expected (Shadrova, 2021). It is thus vital to consider the number of inspected words when defining a topic. The results can differ if the researcher assigns topics based on the first ten or thirty words provided by the algorithm (Allen and Murdock, 2020). Qualitative reading and understanding the original text segments in which the top listed words appear are crucial for accurately interpreting word sets and identifying topics. When working in a group, defining the common guidelines for topic identification in advance is also recommended.
6Topic modelling with the LDA method is thus not a one-size-fits-all solution that could provide the researcher with robust conclusions without a critical analysis of the results. Understanding the limitations of different topic modelling methods is key to successfully using them for research purposes, since quantitative, automated methods can successfully augment the researcher's analytical abilities, but they cannot replace human interpretation (Grimmer and Stewart, 2013). Nonetheless, the topic modelling technique provides an important advantage over the manual approach, specifically with regard to the processing of large data sets, enabling a more robust data-based generalisation than using a small-sample analysis (Jacobs and Tschötschel, 2019). Moreover, topic modelling enables greater objectivity of the results (Müller-Hansen et al., 2021), even though the technique is not entirely objective due to the aforementioned topic definition process based on word sets.
7On the other hand, this is one of the advantages of the technique as the algorithm does not give direct answers but forces the researcher to consider the context when forming the final results (Schmidt, 2012). Topic modelling also enhances systematisation of the analysis and enables a comparatively better reproducibility of the results (Jacobs and Tschötschel, 2019). The popularity and relevance of the technique for the research in the humanities and social sciences are evident from the many publications that use topic modelling as a part of their methodology (see Chapter 4.5).
4.5. Topic modelling of parliamentary debates
1In the humanities and social sciences, particularly in political science, topic modelling is increasingly used as an important technique to complement established, qualitative analytical approaches in analysing large data sets. The results of topic modelling may inform the qualitative analysis (e.g., the researcher can identify relevant texts about a specific topic) or can be used as the principal outcome of the analysis. In this chapter, we provide some examples of both from recent applications of the topic modelling technique to parliamentary data.
2Topic modelling allows us to identify the topics addressed in parliamentary speeches. Schuler (2020), for example, used LDA to analyse the debates in the Vietnamese parliament and compared the results with topics from the news, also extracted with LDA, and with the list of areas under the direct management of the Communist Party (CP). He analysed whether MPs in an authoritarian system, such as the Vietnamese, express their opinions and actively debate important topics. He discovered that they debate only topics outside the CP's direct management, with the party encouraging such debates to pressure the government and blame it for the outcomes of the policies. However, the party does not encourage debates pertaining to areas directly managed by the CP committees. Moreover, debates concerning topics open for discussion do not involve all MPs but mostly those who are not members of the CP and were elected as full-time representatives.
3Chizhik and Sergeyev (2021) also used topic modelling to discover topics in parliamentary debates by analysing three decades of Russian MPs' speeches. They researched whether the activity of the parliamentary parties is related to the public's scepticism regarding the multiparty system as a basis for democracy. They established that parties in the Russian parliament focus mostly on foreign affairs, the economy, and the balance of power between different branches of the government. At the same time, other social issues generate much less debate. Furthermore, speeches from all parties, but especially from the long-established ones, show a strong prevalence for ideological and propagandistic discourse.
4We saw how topic modelling enables acquiring a general overview of the material, which can suffice if the researcher’s aim is, for example, to observe the frequency of topics under consideration in the parliament. But topic modelling can also be used to retrieve more specific results. As parliamentary corpora are usually rich with metadata, topics can be explored in relation to other variables (such as gender, age, party affiliation, mandate etc.), which elicits the topics that stand out most when the selected variable changes. We can thus observe how popular a topic was through time or with a certain party. Curran et al. (2018) used LDA and the analysis of complex networks to elicit topics in the New Zealand parliament, which they then related to MPs and the parties. In this way, they not only retrieved popular topics of parliamentary debates for different periods and interpreted them in the context of external events (e.g., the 2011 earthquake) but also defined the interest of a party in each topic. Their results showed that the Labour Party debated the real estate crisis much more ardently than the then-governing National Party. The latter claimed most of the debate, while the contribution of other parties decreased over time. The MPs' specialisations for different topics also decreased, which is evident from the large number of topics addressed by the majority of the MPs.
5De Campos et al. (2021) used LDA in combination with the available metadata to create thematic profiles of Spanish MPs which reflect the subject matters they discuss in the parliament. Metadata was also used in research by Høyland and Søyland (2019). In 1919, Norway changed its electoral system to become substantially more dependent on party politics, reducing MPs’ autonomy. Høyland and Søyland investigated whether the change in the political system affected the topics in parliamentary debates. They used a version of LDA called structural topic modelling (STM), which considers both the word distributions and the selected metadata when computing the results. They determined that the topic distribution clearly shows that institutional organisation influences the behaviour of the MPs. After the reform that emphasised party politics, the topics showing clear ideological differences between the parties became more frequent, while MPs gave fewer speeches that directly criticized other MPs. Furthermore, MPs more frequently discussed topics of general interest (e.g., the educational system) and more rarely topics related directly to the issues of their constituents (e.g., improving the infrastructure of a remote town).
6Topic modelling enables exploring the context and selecting topics related to a given concept. Müller-Hansen et al. (2021) used a version of LDA called dynamic topic modelling (DTM), which enables the analysis of topics through time.3 They analysed seventy years of German parliamentary debates on coal and explored how they changed through time. The debates from the early years of the corpus show that the MPs considered coal the driver of economic progress and the guarantee of energy safety. Conversely, in recent years MPs primarily talked about energy transition, a general departure from coal, and the flourishing of renewable energy sources. Furthermore, the researchers also established that smaller and younger parties (e.g., the Greens) talk about coal in the context of energy transition and environmental protection more frequently than the other parties.
7Topic modelling can explore the context of a topic or the interplay of topics. Blätte et al. (2020) aimed to discover how frequently migration is addressed in common European politics. They used LDA to create a topic model of parliamentary debates from Austria, France, Germany, and the Netherlands. Then, they selected the three topics which best represented migration and European matters and retrieved all speeches with a high frequency of the two issues. The results show that the debate on migration was predominantly an internal issue in the larger two countries investigated (France and Germany). Particularly in Germany, the European aspect practically disappeared, while the smaller two countries (Austria and the Netherlands) had a larger share of speeches discussing migration from the European perspective.
8In this tutorial, we partially rely on the methodology used by Curran et al. (2018) in the analysis of speeches in New Zealand discussed earlier. However, as our analysis covers a shorter time, we will not split the data into time slices. As seen in the literature, the analysis could be upgraded with structural topic modelling, where we could consider, for example, the party affiliation of the speakers and observe the differences among them. We could also analyse the entire ParlaMint-GB corpus and use dynamic topic modelling to observe the differences in time. Nevertheless, to compare the pre-pandemic and pandemic periods, the use of the LDA method is adequate.
3. Time-based topic analysis can be done with plain LDA, but a separate topic model must be built for each period; the topics must be interpreted and then compared between time periods. Such an approach requires a lot more manual and subjective work, which can negatively affect the results. Another option for temporal topic analysis is dynamic non-negative matrix factorisation (dynamic NMF) (see Gkoumas et al. 2018), which considers the time periods indirectly (Müller-Hansen et al. 2021).