3.1 Corpora
1Language corpora are large collections of carefully selected machine-readable language data which can be used as the basis of linguistic descriptions or as a means of verifying hypotheses about a language. However, corpora are much more than just simple collections of texts in electronic form. They are formatted in one of the standard formats, such as the Extensible Markup Language or XML, and encoded according to a predetermined but usually flexible schema for the representation of texts in digital form. One of the most established encoding methods in linguistics and digital humanities is the Text Encoding Initiative, or TEI.
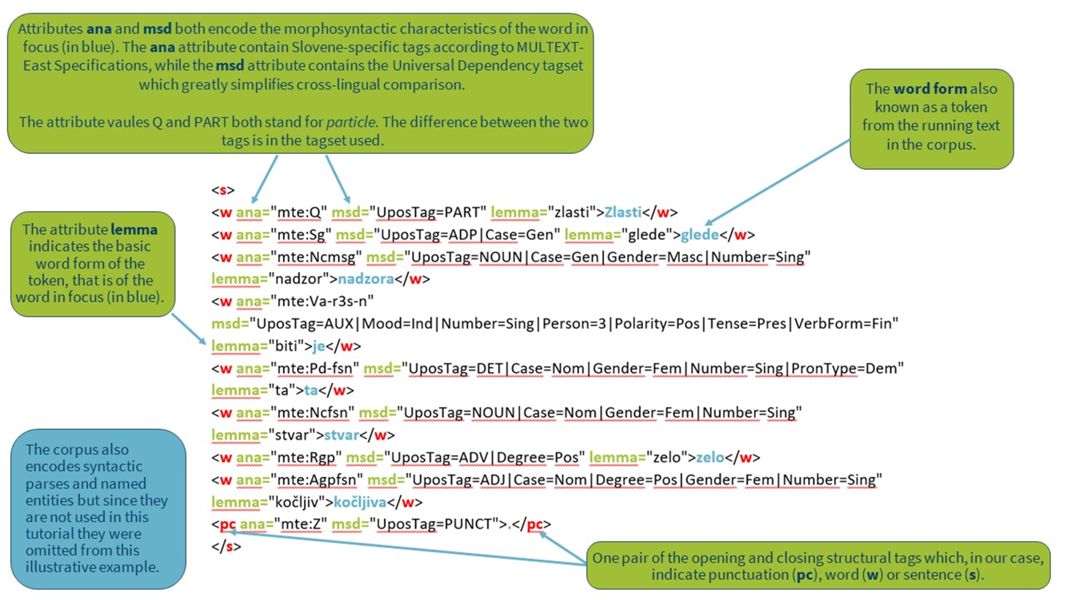
2The basic unit in the corpus is the token, the output of an automatic tokenization process which separates a raw text into smaller units, in our case words. The most common way of forming tokens is based on space between the words as a delimiter. Texts in corpora are linguistically annotated to facilitate corpus searches. The two most basic forms of linguistic annotation are part-of-speech tagging, which marks up the words in running texts with their part-of-speech, and lemmatization, which is the assignment of a base form or lemma to tokens (word forms). Lemmatization is especially important for corpora of morphologically rich languages, such as Slovenian, while less needed for weakly inflective languages, such as English. In addition to linguistic annotation, corpora are also enriched with metadata about the text (e.g., date, type) and speakers (e.g., name, gender) that are needed for the contextualization of the search results but can also be used for more fine-grained corpus queries.
3.2 Concordancers
1Corpora are queried with specialized corpus analysis tools, also called concordancers. Concordancers are either installed on a computer or accessed through a website and can be used to retrieve all instances of a sequence of tokens from the corpus. Many different concordances with similar functionalities exist (see this detailed list for more examples) but some of the most popular ones are the offline AntConc (free) and WordSmith Tools (for which a license needs to be purchased), where you have to load your own corpora, and the online BYU concordancer (free registration required for full functionality) and SketchEngine (free licence for students, teachers and researchers from academic institutions in the EU) which offer a lot of extensive preloaded corpora for many languages as well as the possibility to build and annotate your own.
2Most of the modern concordancing tools offer the following basic corpus analysis techniques that will also be used in this tutorial:
- Concordances show all the hits of the searched word or phrase in the corpus together with its context. They can be randomized or sorted according to the searched word or phrase or by its left or right context, revealing typical patterns in which it is used.
- Frequency lists summarize the frequencies of all the hits that correspond to the corpus query (either based on a selected word (phrase) or metadata) out of context, and can be sorted alphabetically or by frequency.
- Keyword lists highlight what words are prominent in a focus corpus compared to a reference one.
- Collocation lists return a series of words that co-occur with the searched word more often than would be expected by chance.
3Dedicated tutorials for concordancers (e.g., the SketchEngine Quick Start Guide ) as well as general corpus-linguistic courses (e.g., the course Corpus Linguistics: Method, Analysis, Interpretation) are already available online, and we refer to them wherever possible. The focus of this tutorial, however, is to showcase how the functionalities of a popular concordance tool can be utilized and combined on a specialized corpus of parliamentary data in order to answer real-world research questions in a methodologically sound way, as such skills are still lacking, especially for students and scholars of (digital) humanities and social sciences who are interested in the study of socio-cultural phenomena through language use.