1In this section, we will explore a large corpus of Slovenian parliamentary debates. We will demonstrate how basic corpus analysis techniques (for more, see 3) can be used to answer three different research questions:
- In Task 1, we will analyse the representation of women in the Slovenian Parliament. To do this, we will first learn how to create subcorpora. Then, we will learn how to build frequency lists showing the number of speakers and their contribution in the subcorpora.
- In Task 2, we will examine the most prominent topics discussed by female speakers in comparison to their male counterparts and over time. We will gain an insight into the topics by first learning how to extract keywords from the subcorpora. Next, in order to analyse their usage in context, we will learn how to perform concordance analysis.
- In Task 3, we will investigate how topics related to women have been debated by female and male speakers in the past 25 years. We will first learn how to use and compare relative frequencies in subcorpora of different sizes. Then, we will learn how to extract collocations of selected nouns in the subcorpora.
6.1 The siParl 2.0 corpus
1The siParl corpus 2.0 (Pančur et al., 2020) is composed of parliamentary debates of the National Assembly of the Republic of Slovenia from 1990 to 2018. The corpus contains records of parliamentary debates from the period of secession from Yugoslavia until the end of the seventh parliamentary term, minutes of the working bodies of the National Assembly of the Republic of Slovenia from the second to the seventh parliamentary terms, i.e. 1996-2018, and minutes of the Council of the President of the National Assembly from the second to the seventh parliamentary terms, 1996-2018.
2The corpus contains metadata about the speakers (e.g., speaker’s name, gender, role, party), a typology of parliamentary sessions (e.g., regular/urgent/ceremonial meeting) and structural and editorial annotations (e.g., legislative period, session year/title, named entity). The corpus is linguistically annotated for part-of-speech and lemma. It also contains some other annotation layers (e.g., Universal Dependencies, syntactic parsing) which will not be used in this tutorial. The corpus comprises over a million speeches or 200 million words delivered by almost 8,500 speakers (e.g., Members of Parliament, members of the government, ministry representatives, representatives of professional organizations, non-governmental organizations, and interest groups). For general information about corpora and parliamentary records see sections 3 and 4 .
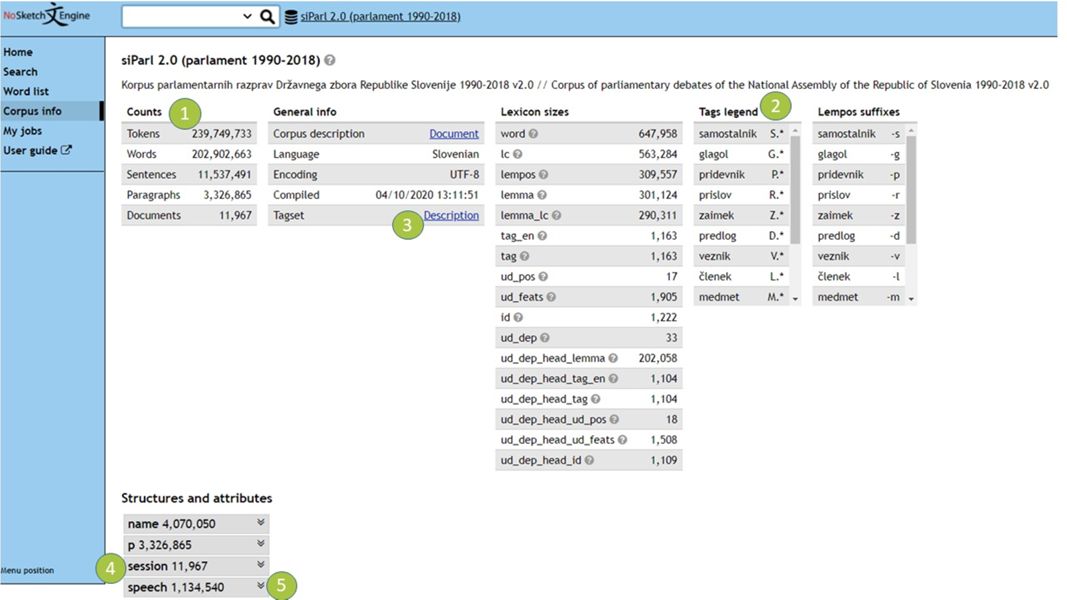
3This information is also summarized in the concordancer (see Figures 3a and 3b):
- Quantitative information about the size of the corpus is provided in the Counts section (see Item 1).
- The basic tags for parts of speech are listed in Tags legend (see Item 2) while the full tagset description is available through the link (see Item 3).
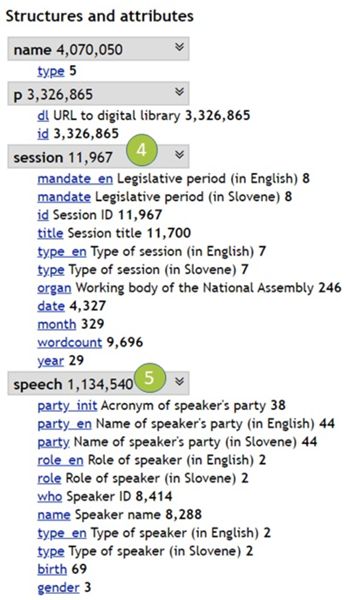
- The corpus is encoded in the form of structural attributes. The session level represents a single session (see Item 4) and conveys information such as session date, type and title (see Figure 3b).
- In addition, structural attributes at the speech level represent one utterance of a speaker (see Item 5) and give information on speaker’s name, gender, role and party affiliation (see Figure 3b).
6.2 TASK 1: Representation of women in the Slovenian Parliament
1The Slovenian National Assembly has 90 MPs, including one representative for the Italian and one for the Hungarian minorities, who are members of nine political parties. Slovenia is one of the youngest EU member states and has seen dramatic changes in gender equality in the past 30 years. While in 1986 when Slovenia was still part of the Federal Socialist Republic of Yugoslavia, female MPs represented almost a quarter of all MPs, in 1992 when the National Assembly of the Republic of Slovenia was convened for the first time, this share notably significantly, so that only in ten MPs was female (Selišnik and Antić Gaber, 2017). During the transition process, when social, political, economic and value systems changed fundamentally, women in Slovenia lost more of the economic and social gains of socialism than men, and were almost completely ousted from key political institutions. But in the seventh parliamentary term (1/8/2014-21/6/2018), which is the last one included in the siParl 2.0 corpus, female MPs held just over 40% of the seats, largely due to legislative measures enforcing gender quotas. 1 According to the EU gender equality value and political power index for 2017, Slovenia ranked among the top 10 EU countries in the proportion of women MPs.
2In Task 1, we are interested in comparing the contents of the siParl 2.0 corpus with the trends observed in parliamentary elections and the Slovenian society.
6.2.1 Creating subcorpora
1By taking advantage of the metadata available in the corpus (see Figure 3b), we split the corpus into parts, called subcorpora, according to the following criteria:
- Gender of the speaker. Each speaker in the corpus is labelled with one of the following gender categories based on the data provided by the official records of the National Assembly: male, female or unknown (in cases when the metadata records are incomplete). In this tutorial we only use the first two categories, male and female, and disregard the speakers with unknown gender.
- Role of the speaker. Each speaker in the corpus is attributed one of the two roles: a Member of Parliament (MP) or external speaker. The latter are invited speakers who are not members of the Parliament, such as members of the government along with representatives of ministries and non-governmental organizations. In this tutorial, we only use the category of MPs since we wanted to study only the contributions by the elected representatives of the Slovenian people.
- Type of the speaker. Apart from the role, each speaker in the corpus is also labelled with one of the following two speaker types: chairperson or regular speaker. Regular speakers are all the speakers in the Parliament who have been explicitly given the floor by the chairperson in charge of the meeting. In this tutorial we only use the category of regular speakers. We intentionally exclude the chairpersons because most of their speeches are regulated by bylaws and other procedures, and are not influenced by their party affiliation, gender or other factors, and would as such skew the results in our particular task.
- Parliamentary term. Each speech in the corpus is categorized into the legislative period in which it was delivered (Term 1 – Term 7). Since it is out of scope for our study, we exclude from our analysis the period of secession from Yugoslavia which is labelled as Term11 in the corpus.
- Working body. The siParl 2.0 corpus contains speeches from plenary sessions, working bodies of the National Assembly (e.g., The Commission for Petitions, Human Rights and Equal Opportunities) and from the Council of the President of the National Assembly. In this tutorial we only analyse the speeches delivered at plenary sessions.
2Based on these criteria, we first create a total of 14 subcorpora, one for each of the seven parliamentary terms containing the speeches by female MPs and one for male MPs, in their role as regular speakers. In addition to these 14 subcorpora, we also create subcorpora that contain all speeches by male and female MPs for each term separately, and for all of the seven terms together.
1A screencast of how to create a subcorpus in NoSketchEngine is available here.
2The created subcorpora and information on their size are available here.
3For advanced users of the tutorial we also provide an example of the CQL commands that are used to generate the following subcorpus:
4Term1-Female2:
5<speech gender="F" & role_en="MP" & type_en="Regular speaker"/> within <session mandate_en="Term 1 .*" & organ="Državni zbor Republike Slovenije"/>
6This command searches for all utterances (attribute speech) spoken by speakers whose gender is female (attribute F), whose role is member of parliament (attribute MP) and whose type is regular speaker(attribute Regular speaker) within the texts from the first parliamentary term (attribute Term 1 .*) that were given in the National Assembly of the Republic of Slovenia (attribute (in Slovene): Državni zbor Republike Slovenije).
7In order to compile a subcorpus of speeches delivered by male MPs, we only need to change the speech gender attribute in the CQL command above (i.e., speech gender="M"). Similarly, if we want a subcorpus containing all speeches from all terms delivered by both female and male MPs, we first have to include both genders through the speech gender attribute (i.e., speech gender="F|M") and all terms through the session mandate attribute (i.e., session mandate_en="Term .*").
6.2.2 Using frequency lists
1Using the subcorpora created in the previous step, we will analyse the contribution of the female and male MPs across time with the help of one of the most basic corpus techniques, called frequency lists. These display query results from most frequent to least frequent. This technique can, for example, be used to build a frequency list of all the words uttered in the whole parliament or by a specific speaker. In this task, we will use this function to obtain information on the number of male and female MPs in each parliamentary term, and the number of speeches and tokens they uttered.
1A screencast of how to create a frequency list in NoSketchEngine is available here.
2An example of two frequency lists can be seen in Figure 4.
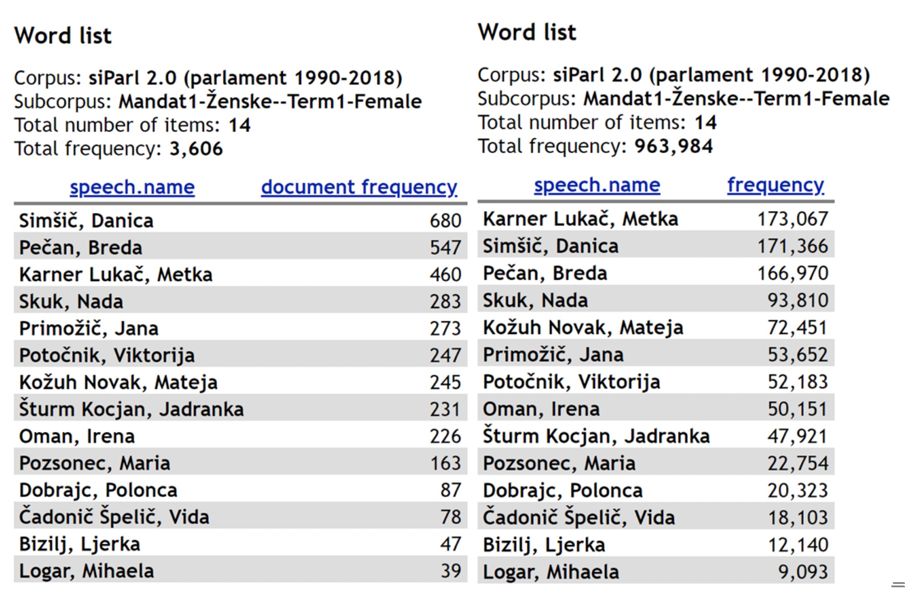
2As can be seen from Figure 4, there were a total of 14 female MPs in Term1 who collectively uttered more than 3,500 speeches, with just under one million tokens. On average, this is almost 260 speeches or 69,000 tokens per MP. However, the contribution per MP is very uneven, ranging from nearly 700 speeches, or more than 170,000 tokens, to fewer than 40 speeches comprising around 9,000 tokens.
3Measured in speeches, the first-ranking speaker is Danica Simšič, a member of the Democratic Party of Slovenia, a small opposition party who was elected to the Parliament only in the first term and contributed 680 speeches, or almost 19% of all the speeches in the entire subcorpus, which is almost three times the female average. The share of the speeches by Danica Simšič was calculated by dividing the number of her speeches by the number of all the speeches by female MPs (see Figure 4, left: Total frequency and Simšič, Danica). The ratio with regard to the average was calculated by dividing the number of speeches by Danica Simšič with the average number of all speeches by female MPs, which we get by dividing the total number of speeches by female MPs with the number of all female MPs (see Figure 4, left: Total frequency and total number of items).
4Measured in tokens, the female MP with the largest contribution in this subcorpus is Metka Karner Lukač, member of the Slovenian People’s Party, the oldest party in Slovenia, who gave speeches with 173,067 tokens or 18% of the entire subcorpus, nearly three times the average. The MP with the lowest number of speeches as well as tokens is Mihaela Logar, a member of the Slovenian People’s Party, who spoke 39 times and gave speeches with just over 9,000 tokens in her four-year term as MP, which is nearly 20 times less than the first-ranking speaker. It is interesting to note that approximately half of all contributions can be attributed to only three MPs: the two mentioned above and to Breda Pečan, member of the Social Democrats, whose speeches on average were also the longest. This information can be extracted from data on the average length of speeches for individual MPs, which we get by dividing the total number of tokens for the individual MP (see Figure 4, right) with the total number of speeches by this particular MP (see Figure 4, left).
6.2.3 Comparative analysis
1For a comparative analysis of the representation of men and women in the Slovenian Parliament over time, we record the number of MPs and the number of tokens in each of the 14 subcorpora (see section 6.2.1 Creating subcorpora). Since the concordancer does not provide such summary tables, we manually enter the values into a spreadsheet, as can be seen in Table 1. Visualization of the results can be seen in Figure 5 and Figure 6.
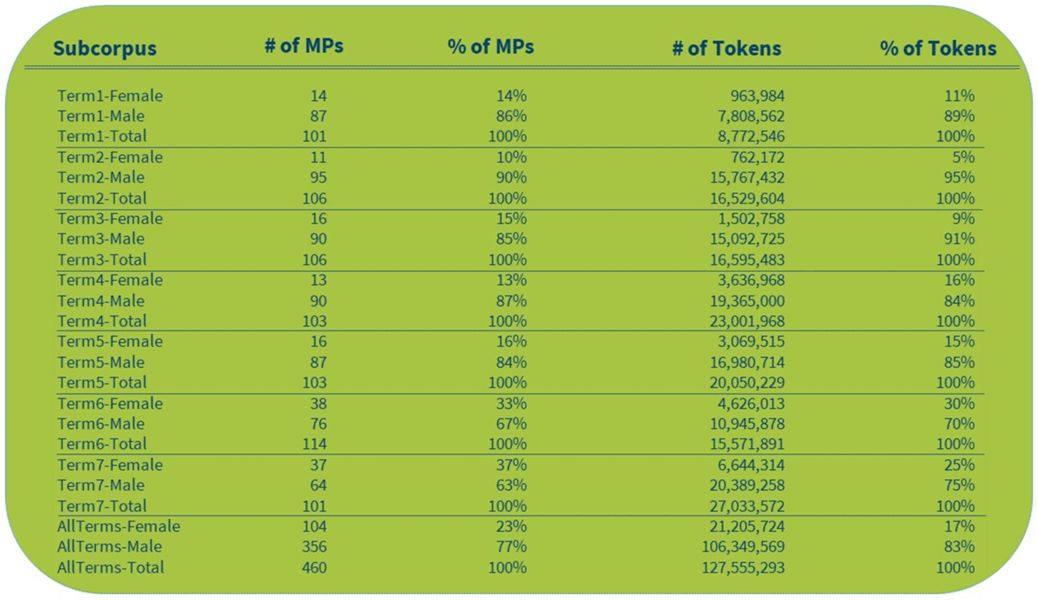
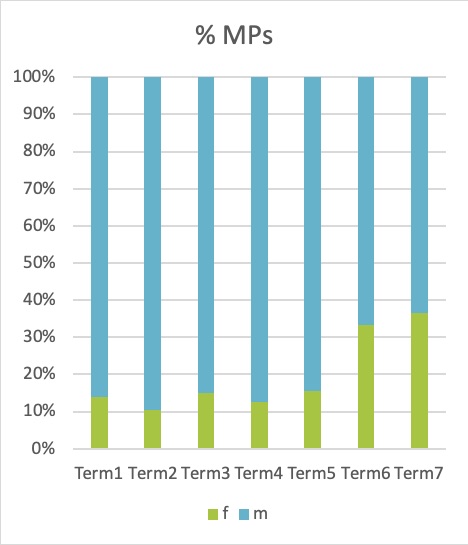
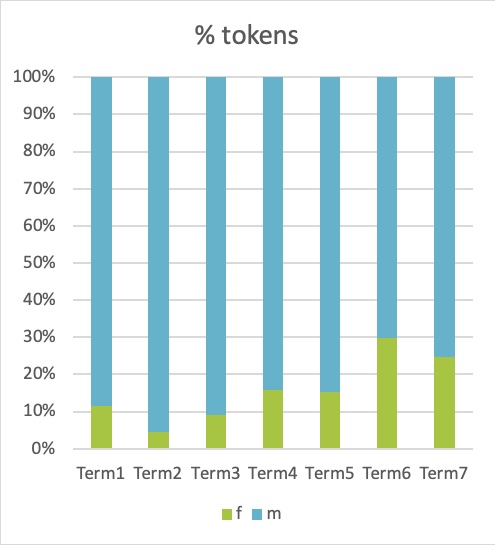
2The results show that the share of tokens in speeches by female MPs gradually increases along with the number of female MPs in the Parliament. A notable leap in the representation of women can be observed in the last two terms covered by siParl 2.0, which is most probably due to the adoption of gender quotas, according to which, since 2011, 35% of the candidates must be women (Selišnik and Antić Gaber, 2017). Importantly, despite quotas being one of the most successful measures to increase the number of female MPs (Selišnik and Antić Gaber, 2017), our corpus analysis shows a large discrepancy between the number of female speakers and the amount of tokens in their speeches. While election results are easily accessible and frequently used by researchers and analysts, the amount and content of the speeches has been much less readily available and studied much less comprehensively outside corpus linguistics, which is a gap we aim to help close with this tutorial. By looking into the created subcorpora, we can see that for female MPs there is a clear tendency to contribute a lower share of content than would be expected given their share of speakers. This is especially true for Term2 where they produced two times fewer tokens than would correspond to their speaker share. In fact, only in Term4 was women’s contribution marginally greater than their share of seats in the Parliament. Therefore, we can conclude that having more elected female MPs does not directly mean that their voice is more present in the National Assembly. Nonetheless, as the number of female speakers in the Parliament has been on the rise in recent years, the number of their speeches has started increasing as well. From as little as a tenth of all the speeches given in the Parliament during the first five parliamentary terms by female MPs, the contribution of female MPs has risen to almost a third in the last two parliamentary terms covered by our corpus.
6.3 TASK 2: Issues addressed by women
1Studies of female political discourse have shown that women tend to debate different topics to men. More about the impact of gender on language can be found in the section 5.
2In Task 2, we are interested in comparing the topics discussed by female MPs in siParl 2.0 with those discussed by their male counterparts. While topic classification is readily available for some parliamentary corpora, as in Nanni et al. (2018), this is not the case for siParl 2.0. Topic classification could be derived automatically, as in Karan et al. (2016), however, the goal of this tutorial is to demonstrate the potential of parliamentary corpora research via concordancers without requiring programming skills, which is why we opt for a two-step manual approach. Moreover, manual approaches are especially appropriate for highly specific topic classification tasks such as ours, for which no pre-trained models or training data exist. It should be noted that both automatic and manual annotation approaches produce errors, but that we can avoid those due to annotator’s subjectivity by employing multiple annotators. The final quality of such manual annotations can be verified with statistical tests that report on the inter-annotator agreement.
6.3.1 Extracting keywords
1To enable the comparative analysis we will first use a well-known corpus analysis technique called keyword extraction. It compares a focus corpus against a reference corpus in order to identify the most distinguishing vocabulary of the focus corpus. The focus corpus is the corpus or subcorpus under investigation. The reference corpus is typically a large representative corpus of a given language but can also be any other corpus or subcorpus we wish to use as the reference for comparison. In this task, we will contrast the female-male pairs of the siParl 2.0 subcorpora to uncover the most prominent issues discussed by the MPs in the Slovenian Parliament.
1A screencast of how to generate a keyword list in NoSketchEngine is available here.
2The generated keyword lists (using lowercased lemmas) are available here:
3We first export the keyword lists for each of the four subcorpora into a spreadsheet and then manually annotate the data (see section 6.3.3).
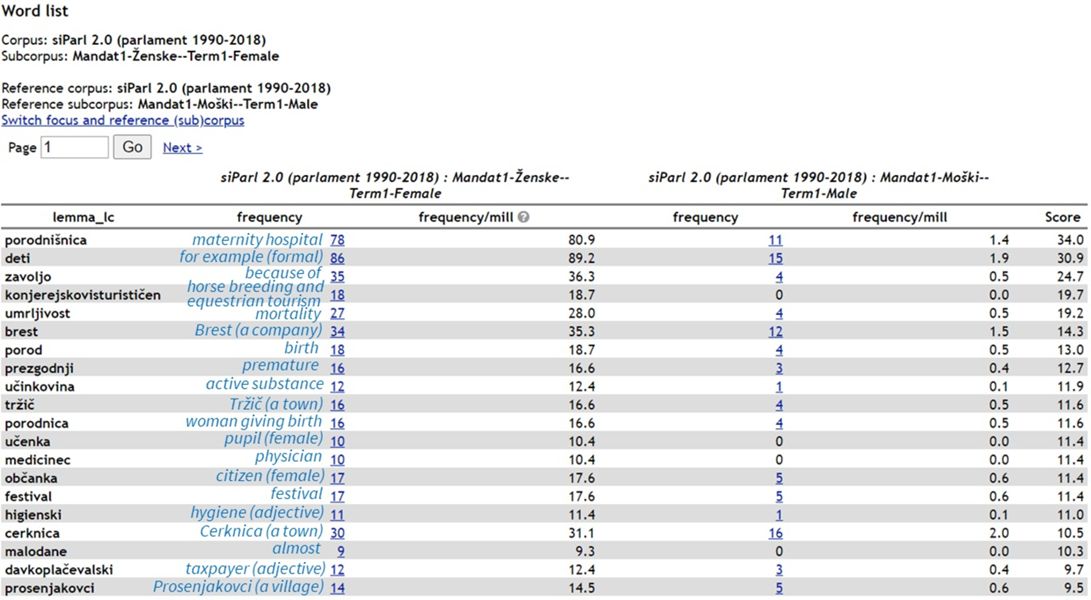
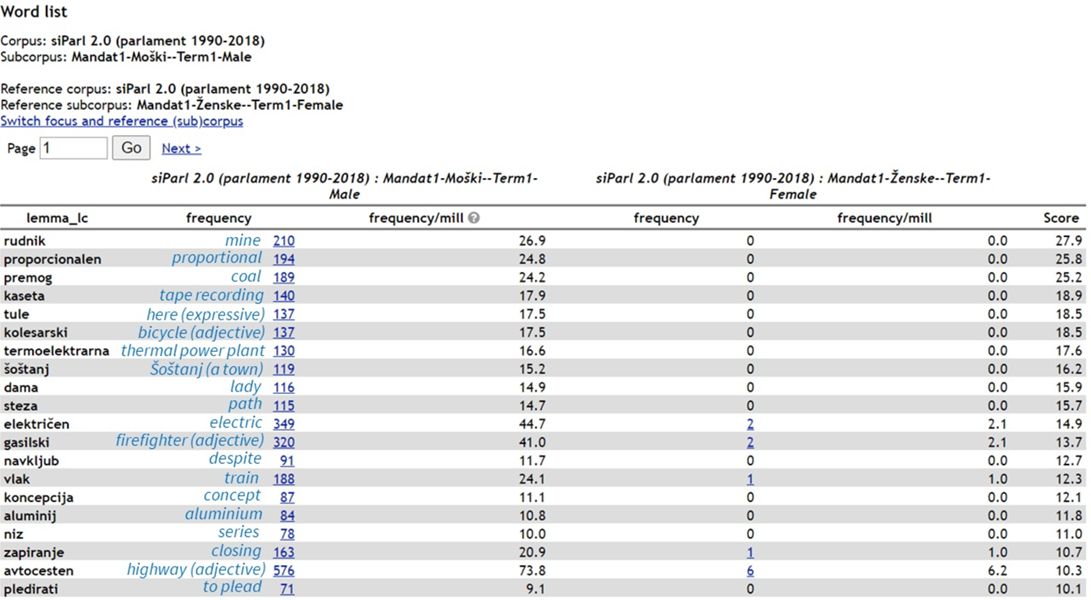
2Figures 7 and 8 show the 20 top-ranking keywords for female and for male MPs in Term7, using the Simple Maths statistics. Stark differences can be observed: while the majority of all the displayed keywords for female speakers are related to Healthcare, the key male vocabulary belongs to the domains of Foreign affairs, Infrastructure and Justice.
6.3.2 Analysing concordances
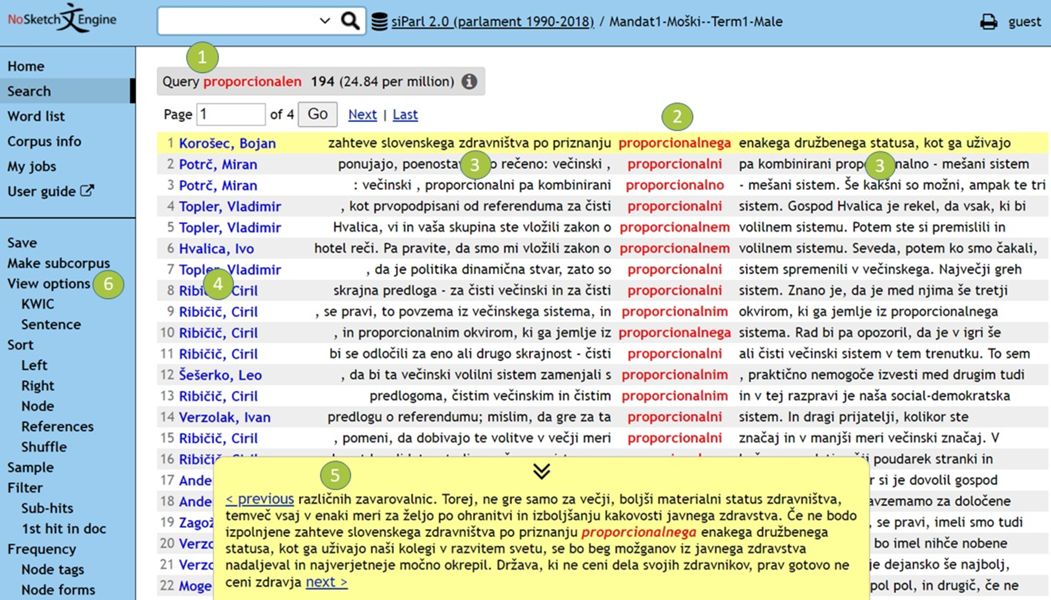
1For further analysis, we select the 100 top-ranking key lemmas, excluding personal names, from the four generated keyword lists. Our goal is to manually categorize each of them into topics after inspecting their concordances, which are lists of all instances of the search words in their contexts, as shown in Figure 9:
- Concordances can be displayed directly by clicking on the key lemma in the keyword list. At the top of the page that appears, the selected lemma is displayed along with its hits (see Item 1).
- The words in red at the centre of the screen (see Item 2) are the hits of the search word in our subcorpus and the text in black (see Item 3) is the context.
- The text in blue on the left (see Item 4) is the metadata for the concordances, in our case the speaker.
- The context can be further extended by clicking on the desired concordance (see Item 5). The same procedure can be followed for obtaining more metadata by clicking on the speaker.
- Alternatively, you can also tweak the view parameter in View options (see Item 6) and display more metadata or a wider context.
6.3.3 Comparative analysis
1Because the main role of the Parliament is legislative, and because the legislative and budgetary discussions are structured according to the ministries responsible for them, we will use the list of 14 ministries of the current Slovenian government as categories for topic analysis. The categories are listed in Table 2. While several other lists of topics could be used, this one seems the most natural in the specific setting of parliamentary discourse. In addition to these 14 categories, the list is extended with another fourcategories for keywords that cannot be listed elsewhere: Multiple (for keywords used in discussions on several topics); style (for clearly colloquial or jargon keywords used only by specific speakers); ideology (for keywords used for ideological labelling, e.g., “partijski/partisan (derogatory, adjective)”); and interactional/procedural (for keywords referring to other MPs or to procedural matters). Illustrative examples of manual annotation of the 10 top-ranking keywords by female and by male MPs are given in Table 3.

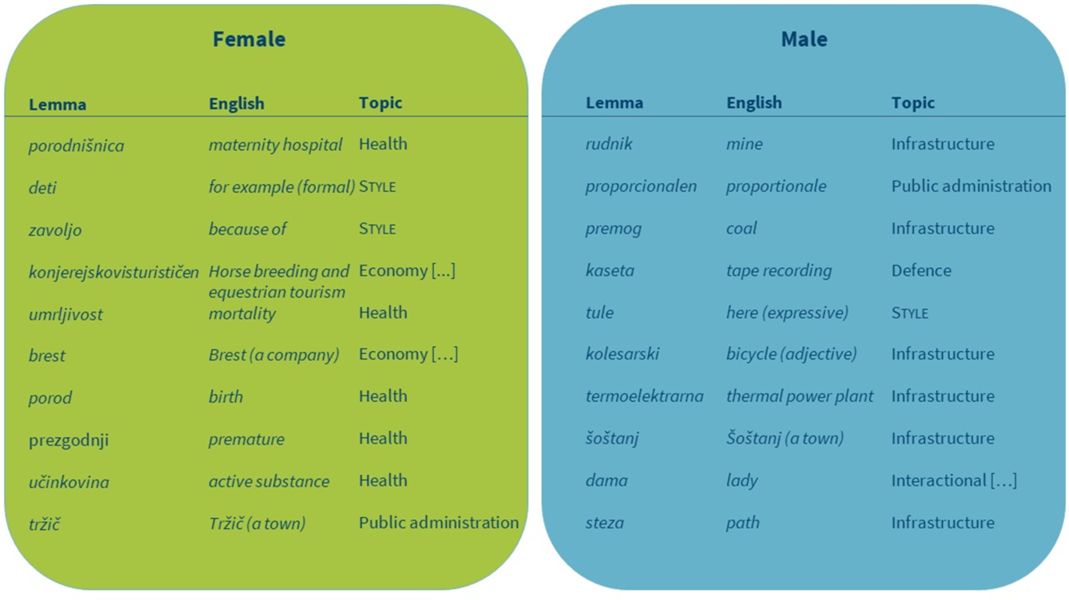
2Tables 4 and 5 contain summarized results of the manual annotation of 100 top-ranking key lemmas for female and male MPs in Term1 and Term7, respectively. The results show that the range of topics is comparable through time and between the genders. Despite the similar number of identified topics, men and women differ a great deal in their most prominent one.
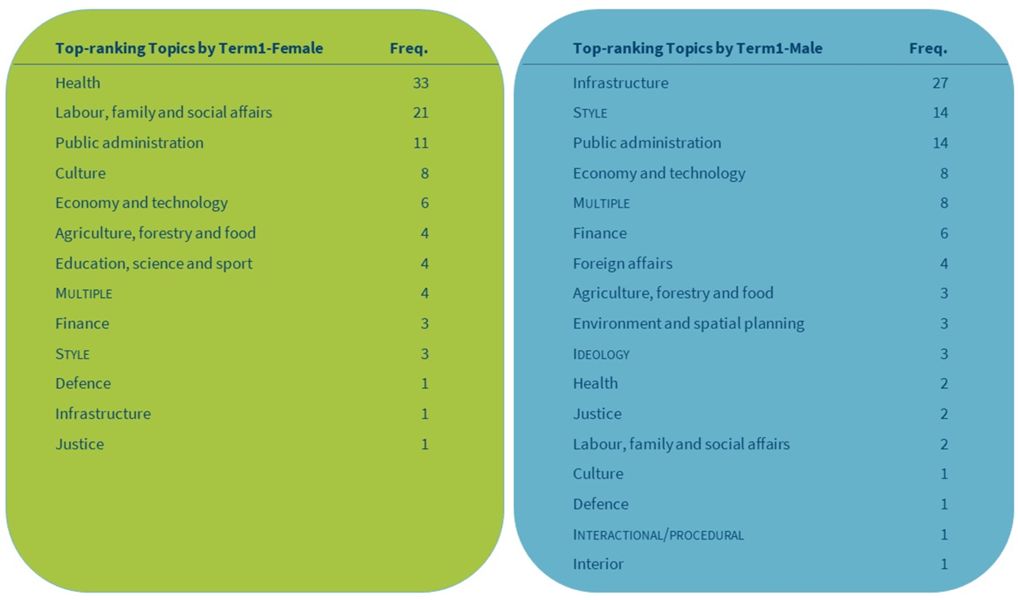
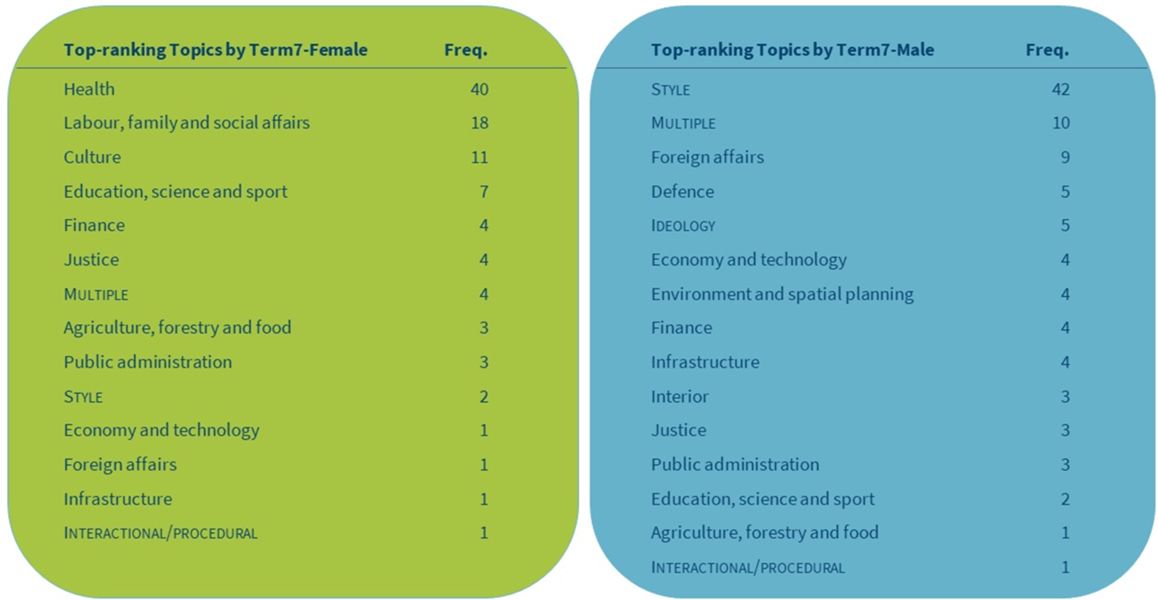
3In Term1, the majority (54%) of all the analysed female keywords belong to only two topics (Health and Labour, family and social affairs), whereas the two most common topics of male MPs with a similar share (55%) are Infrastructure and Public administration. In Term7, the two prevailing female topics not only remained the same but also slightly intensified (58%) while for male MPs the most prominent topic became Foreign affairs. While the division of topics between genders cannot be explained through simple corpus analysis, both an intense focus on Health and Social affairs in the female subcorpora, as well as the shift from Infrastructure and Public administration to Foreign affairs in the male subcorpora are a good reflection of the state of affairs. At the time of independence, the new-born state of Slovenia had to create its own public administration and re-build its infrastructure, which required intensive discussions in the first parliamentary term. The last term, on the other hand, was marked by more intensive international trade as well as greater international security threats, which warranted legislative and budgetary decisions in the parliament. The intensified discussions on Health issues as well as a continued focus on Social issues in Term7 were largely due to heavy pressure on the budget due to the severe economic crisis in that period, which also negatively impacted the already crumbling public health system.
4We can also observe that in Term1, men and women attached similar importance (according to the share of the analysed keywords) to more topics than in Term7 (five shared topics with equal importance in Term1 vs. three topics in Term7). Thus, in Term1, men debated slightly more than women on Public administration (M: 14% vs. F: 11%), Economy and technology (M: 8% vs. F: 6%) and Justice (M: 2% vs. F: 1%), and women debated slightly more on Agriculture, forestry and food (M: 3%, F: 4%), while MPs of both genders debated equally on Defence (1%). In Term7, on the other hand, only three topics appear as equally important to male and female MPs: Finance (4%), Justice (3%) and Public administration (3%). For a more in-depth analysis, it may be interesting to look into the specific ways (if any) in which female and male MPs approach and discuss the key issues of these topics.
5The data shows that female-specific topics are Education in Term1, and Health, Labour, family and social affairs and Culture in Term7. It is surprising that these last three topics, which are the top three for women, do not appear on the list of topics for men, while we can find the top topics for men (Infrastructure, Public administration, Foreign affairs) on the women’s list (although with a negligible share of the total). Male-specific topics, on the other hand, are Environment and Interior in both parliamentary terms, Foreign affairs (in Term1) and Defence (in Term7). Surprisingly, it can be observed that Economy and technology, which is a topic present in both terms for both genders, drastically loses its saliency in the subcorpus of female speeches in Term7.
6Apart from the different areas of interest, the results also show that male and female MPs have different debating styles. In both terms, male MPs use considerably more stylistic words (i.e., clearly colloquial or jargon words observed only from specific speakers) than their female counterparts. In fact, the usage of such words by male MPs tripled in Term7 compared to Term1, which on the one hand indicates the greater casualness of male MPs in general, as well as highlights a change in the debating culture, which in the last two decades has become more ludic and informal. We also observe that ideological words, which tend to be polarizing, are only used by the male MPs. This is in line with findings from the literature, according to which men’s conversational strategies are more aggressive and competitive, whereas women’s debating style is more cooperative (Coates, 1997). It should be noted that these results would need to be confirmed by a more detailed analysis, since some recent studies have challenged the clear-cut gender difference in debating styles as being an overgeneralization (cf. Ilie, 2013).
7Our findings point out notable differences in the roles and interests of male and female MPs which is in line with previous studies showing that women focus more on the so-called soft topics than men. Diachronic comparisons reveal that Health and Social issues remain the top priority for female MPs, while the focus of male MPs shifted from Infrastructure andPublic administration towards Foreign affairs. In Term1, the most prominent common topic was Public administration, while in Term7, Finance became the most often discussed topic for both male and female MPs. This, however, does not mean that female MPs now debate more on the hard topics, quite the contrary, in fact, as our analysis showed that in Term7 women focused more on soft topics than in Term1.
6.4 TASK 3: Topics related to women
1This task is inspired by related work (see Blaxill and Beelen, 2016) which investigated how frequently, by whom and in what way are topics related to women, such as women’s rights, equality, discrimination, etc., addressed in parliamentary history. It is interesting that the impact of gender seems to be prominent even in countries with high representation of women in parliament, such as Sweden, for which Bäck et al. (2014) found that female MPs discuss the so-called hard policy issues less frequently. Furthermore, Antić Gaber and Ilonszki (2003) state that society usually expects women MPs to be actively involved in different policy areas than men, in those that are particularly salient to women because of women’s historic role in society or because those areas directly affect women’s lives.
2Given that debates about gender equality are still dominated by issues pertaining to women’s unequal and special role in society, which directly impacts their rights as well as discriminatory practices, we are interested in Task 3 in comparing how male and female MPs in the Slovenian Parliament express themselves when addressing topics related to women by focusing on their use of the noun “ženska/female” as an explicit indicator of debate on such topics.
6.4.1 Working with frequencies
1First, we are interested in how frequently the lemma of the noun “ženska/female” is mentioned by male and female MPs in different time periods (1992-2018). We query all the subcorpora and record all the frequency counts of the lemma in a spreadsheet, with the results shown in Table 6. Because we are interested in comparing subcorpora of different sizes, it is important to use normalized frequencies instead of the absolute ones, as these raw frequencies can be misleading. Looking for example at the raw frequencies for Term2 (F: 190; M: 794), we could conclude that male MPs mention the noun “ženska/female” four times more often than their female counterparts. But, because the female subcorpus in that parliamentary term is much smaller than the male subcorpus, the normalized frequency, which calculates the frequency based on the same number of words in each subcorpus (in our case a million words), shows that the noun is actually five times more frequent in the female subcorpus (249.29) compared to the male one (50.36).
1If you would like to see how to query a subcorpus for the lemma, please watch the screencast on how to extract collocations in NoSketchEngine (min. 00:09–1:24) here.
2A concordance list for the lemma of the noun “ženska/female” is available here:

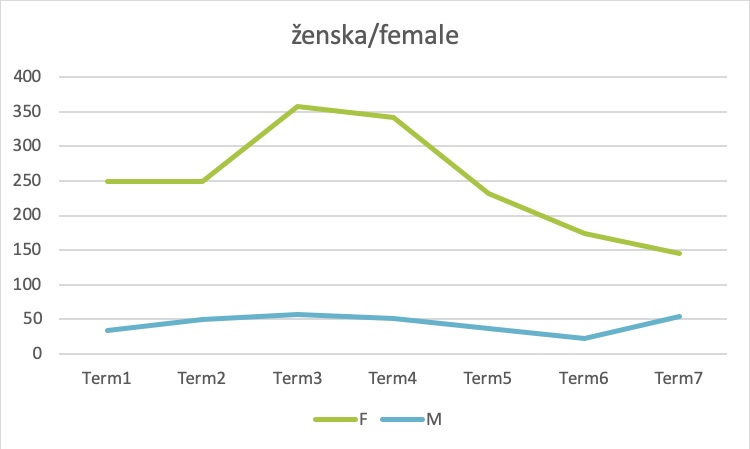
2Overall, the normalized frequency of the word for the entire time period is nearly five times higher in the subcorpus of female MPs compared to their male counterparts (221.21 vs. 45.99). As can be seen from Figure 11, female MPs in general tend to talk more about women than their male counterparts. However, if the period between Term2 and Term4 (1996–2008) saw a strong emphasis on topics about women among female MPs in comparison to male MPs, we can observe a steep downward turn in the female subcorpus in more recent terms.
3The most striking results for the female subcorpus are observed in Term3 and Term5. In Term3, the normalized frequency of the word reached a record high, which might be a consequence of lower numbers of female representatives in the previous two parliamentary terms and their unequal position in society overall. However, as the same trend is observed in the male subcorpus, it appears that other reasons had to contribute to this result as well. For a better insight into the phenomenon we perform qualitative analysis by inspecting 50 concordance lines for the five most active male MPs. They show that legislation regulating specific issues which are particularly linked to women was extensively debated at the time (i.e. legislation related to equal opportunities, artificial insemination with biomedical assistance and quotas). Almost a decade later, in Term5, there was a sudden reduction in the number of mentions of the word in the female subcorpus, which even dropped below the frequency before the year 2000 despite a higher number of female MPs. Term5 coincides with the period of a major global economic crisis, which badly hit Slovenia and probably took centre-stage in parliamentary discussions, but this would need to be confirmed through further investigation and contextualization using qualitative methods, such as concordance analysis.
4It is also interesting to observe that in Term4 despite there being the second lowest number of female MPs, the noun “ženska/female” remains very frequent as opposed to in Term6 and Term7, when the number of female MPs was considerably higher but the frequencies of the queried word almost two times lower. As previously observed in the overall production of female MPs (see 6.2.3), where we found a large discrepancy between the number of female speakers and the amount of words they uttered, these results again show that a higher number of female MPs does not guarantee a strong discussion of issues related to women in the Slovenian Parliament.
6.4.2 Extracting collocations
1Next, we will demonstrate another popular corpus analysis technique called collocation extraction, which identifies word combinations that co-occur more often than would be expected by chance based on statistical significance tests. While collocations are most typically used in lexicography and related fields of applied linguistics, we will use them as a vehicle to explore the concepts or themes that are debated in the Slovenian Parliament.
2To be able to dive deeper into the issues addressed when talking about women, we will investigate collocations of the noun “ženska/female” from two siParl 2.0 subcorpora, one containing the female speeches from all seven parliamentary terms ( AllTerms-Female) and the other comprising male speeches from the same time span (AllTerms-Male).
1A screencast of how to extract collocations in NoSketchEngine is available here.
2First, we extract collocations in the range one word to the left and one word to the right of the headword (i.e., the lemma of the noun “ženska/female”) with five occurrences as the minimum frequency in the corpus and three minimum co-occurrences with the headword in the defined window size. While window size and minimum frequencies can be set manually and depend on type and frequency of the word under investigation, corpus size, and our research goal, we want to limit our analysis for this tutorial to fixed multi-word expressions, thereby using a very narrow window and strict minimum frequency criteria.
3We use the logDice statistic measure to measure the association strength between words. While several other collocation measures are also offered by the NoSketchEngine concordancer, such as Mutual Information or T-score, we opt for logDice because it is not affected by the size of the corpus and can therefore be used to compare the scores between subcorpora of different sizes.
4The two collocation lists for the headword “ženska/female” are available here:
5We then import both collocation lists into a spreadsheet and manually analyse the data.
6.4.3 Comparative analysis
1We take 100 top-ranking collocation candidates from each list and manually divide them into three categories: female-only, male-only and shared. Next, we categorize each collocation candidate into one of seven thematic clusters that are inspired from a close reading of corpus concordances, as illustrated in Table 7. Collocation candidates that are grammatical words (such as prepositions) and are not used in concordances with a prevailing theme are assigned the label Multiple.
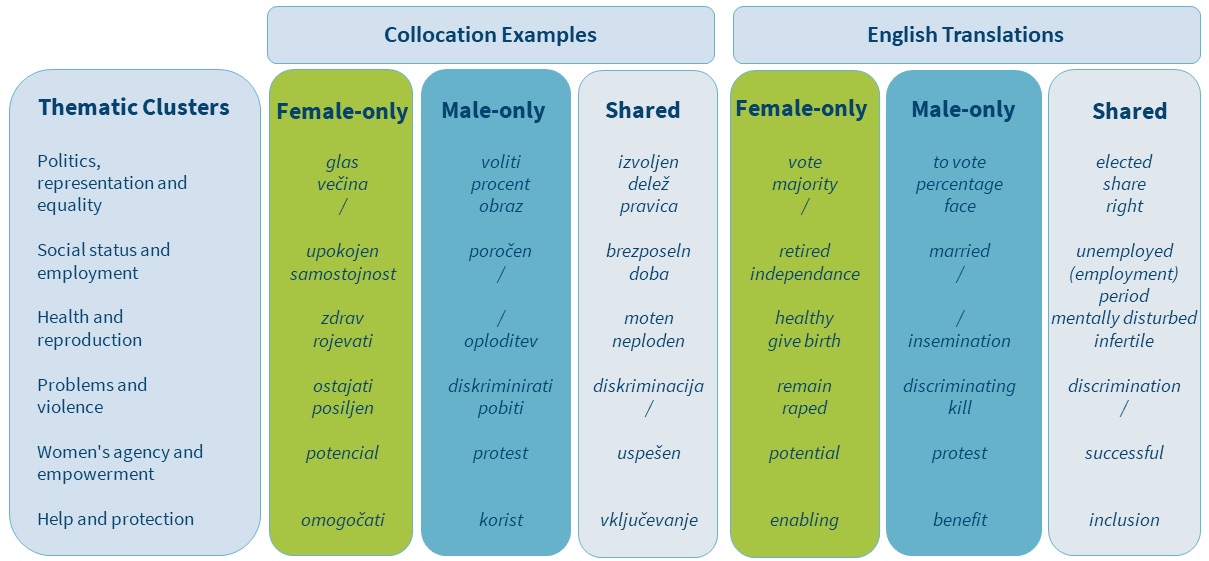
2The results presented in Table 8 show that just over half (51%) of the collocations are shared between MPs of both genders, revealing common ground in the understanding of women’s position in modern society. The great majority of the shared collocations (nearly 70%) fall under the first two thematic clusters: Politics, representation and equality and Social status and employment, and refer to concepts related to representation of women (e.g., “participacija/participation”), their social status (e.g., “samski/single”) and equality (e.g., “emancipacija/emancipation”).
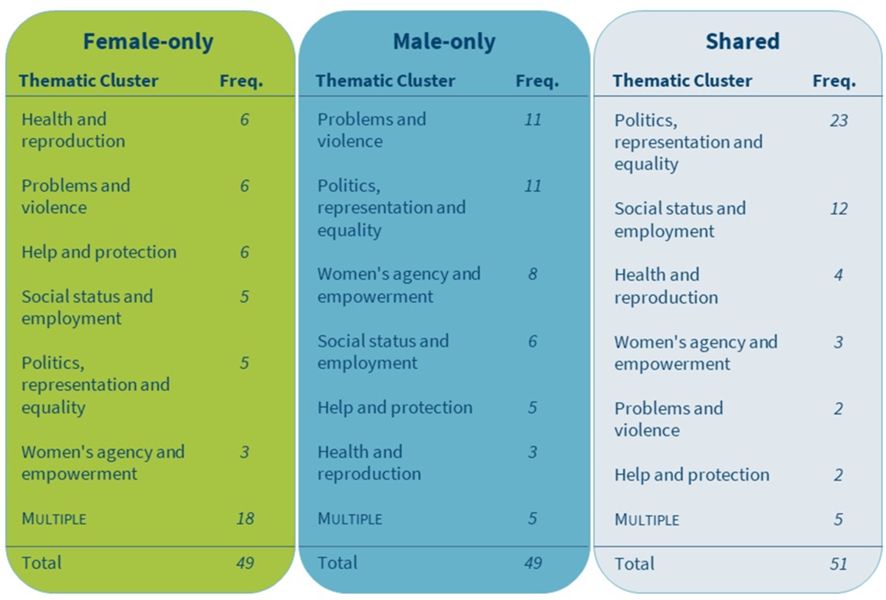
3It can also be observed that the female subcorpus contains comparable representation of all but one thematic cluster which together cover almost 60% of the collocations. The only exception is the cluster Women’s agency and empowerment. Collocations that belong to this thematic cluster are approximately twice less frequent than collocations belonging to any other cluster. In the male subcorpus, on the other hand, the majority of collocations (61%) fall under only three thematic clusters, namely Problems and violence, Politics, representation and equality, and Women’s agency and empowerment. Furthermore, a detailed look into annotations reveals that men mainly focus on women’s social status (e.g., “poročen/married”) and problems (e.g., “zatiranje/oppression”), as well as their agency and empowerment (e.g., “sposoben/capable”), while not focusing on issues related to women’s employment and health. On the other hand, collocations from the female subcorpus first and foremost refer to health issues (e.g., “zdrav/healthy”) and measures related to help and protection (e.g., “omogočati/enabling”). These are closely followed by words referring to women’s social status (e.g., “izobrazba/education”) and violence (e.g., “posiljen/raped”), which is again contrary to the male subcorpus where more emphasis is given to problems not directly linked to violence (e.g., “poniževanje/humiliation”). In addition, similar to the male subcorpus, employment-related words do not appear in the female subcorpus among the top 100 collocation candidates.
4These results indicate that female MPs try to address the multitude of issues that women face in various areas of life, from health related issues to the aggression suffered by women and difficulties with entering into politics, while male MPs focus more intensely on the unequal place of women in society and view women as active participants in the process of change. These results also confirm the findings of Antić Gaber and Ilonszki (2003) who looked at a shorter period (1996–2004) of female MPs’ activity in the Slovenian Parliament and showed with diverse, non-corpus linguistic methods that there exists a clear difference between the legislative priorities of male and female MPs, identifying similar topics to those in our analysis.
5Our final observation pertains to the high number of grammatical words found in the female subcorpus, which are almost four times more frequent than in the male subcorpus. These collocation candidates in the female subcorpus mainly consists of adverbs, followed by prepositions, conjunctions, pronouns and numerals, while in the male subcorpus they predominantly include numerals. Similar to what we saw in the keyword analysis (see 6.3.3), this once more points to a different debating style of female MPs. This is in line with related work where it has been found that women tend to employ more language features such as hedges, politer forms and tag questions (Coates, 1997), more intensifiers and adjectives, especially evaluative ones (Poynton, 1989) and more personal pronouns than men, whose language includes more numbers, articles and prepositions (Newman et al., 2008).
1. The share is based on the official number of all female MPs listed in Kustec (2017) and then divided by the number of all MPs (i.e., 90). This share is slightly higher than reported in our analysis for which we strictly took only the corpus data throughout the tutorial. Since all of the elected MPs rarely serve the whole term, they are then replaced by other MPs. This is reflected in the corpus which includes all MPs, not just the ones listed at the time of the elections. According to corpus data, the total number of MPs per term is thus greater than 90.
2. Since this tutorial is offered both in English and Slovene, we gave the subcorpora in the concordancer bilingual names. However, for clarity and conciseness, we are only using the English part of the subcorpora names in this version of the tutorial.
3. Due to an error in corpus metadata attributed to one MP (specifically, to an MP named Geza whose gender was erroneously marked as female, most probably due to a combination of the ending –a, which in Slovene is typical of nouns of female grammatical gender, and low frequency of the name), the data for Term6, at the time of analysis, does not reflect the official number of female MPs which is according to Kustec (2017) 39 instead of 38 as found in the corpus.