3.1 Korpusi
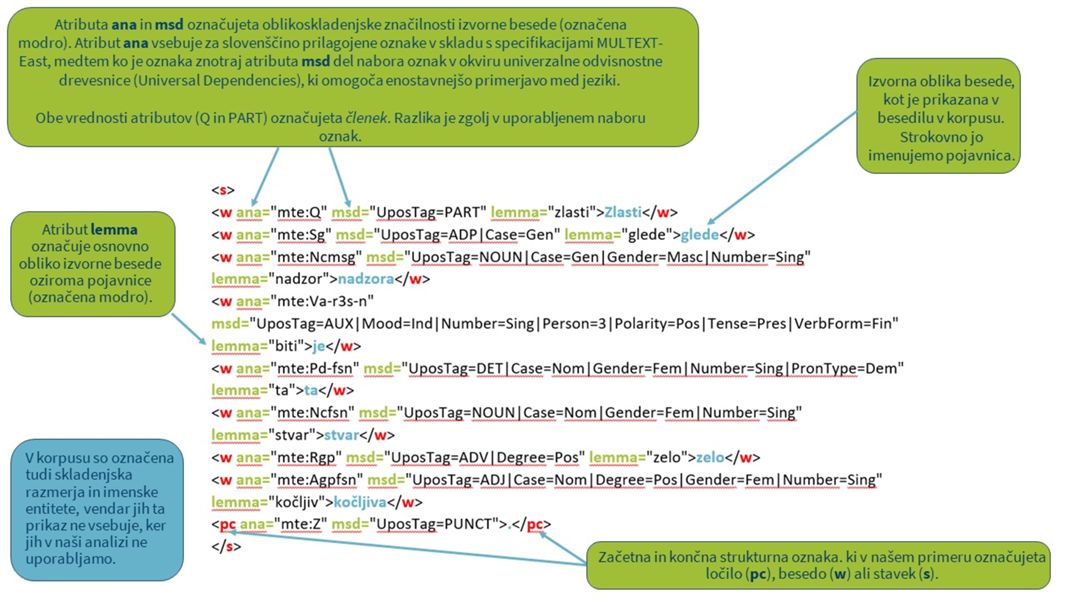
1Besedilni korpusi so obsežne zbirke skrbno izbranih strojno berljivih jezikovnih podatkov, ki jih lahko uporabimo za pripravo jezikovnih opisov ali za preverjanje hipotez o jeziku. Vendar pa so korpusi veliko več kot le zbirke besedil v elektronski obliki. Oblikovani so v enem od standardnih formatov, kot je razširljivi označevalni jezik oziroma XML, in kodirani v skladu z vnaprej določeno, a prilagodljivo shemo za predstavitev besedil v digitalni obliki, med katerimi je v jezikoslovju in digitalni humanistiki najbolj uveljavljen standard TEI.
2Osnovna enota korpusa je pojavnica, ki jo dobimo z avtomatskim postopkom tokenizacije, pri katerem je izbrano besedilo razdeljeno na manjše enote, v našem primeru na besede. Običajno se pojavnice določajo glede na presledke med besedami. Za bolj poglobljeno analizo so besedila v korpusu jezikoslovno označena. Najosnovnejši obliki jezikoslovnega označevanja sta oblikoskladenjsko označevanje, s katerim besedam v besedilih pripišemo besedno vrsto (npr. glagol), in lematizacija, pri katerem pojavnicam (besednim oblikam v različnih sklonih) pripišemo osnovno slovarsko obliko oz. lemo. Lematizacija je pomembna zlasti za korpuse morfološko bogatih jezikov, kot je slovenščina. Poleg jezikoslovnih oznak so v korpus dodani tudi metapodatki o besedilu (npr. datum, vrsta) in govorcu (npr. ime, spol), ki so pomembni za kontekstualizacijo rezultatov, vendar se lahko uporabljajo tudi za izvajanje natančnejših korpusnih poizvedb.
3.2 Konkordančniki
1Po korpusih iščemo s specializiranimi orodji, ki se imenujejo konkordančniki. Nekatere konkordančnike moramo pred uporabo namestiti na osebni računalnik, drugi pa so dostopni neposredno prek spleta. Uporabljamo jih za iskanje vseh pojavitev pojavnic v korpusu, ki ustrezajo našemu iskalnemu pogoju. Na voljo je veliko konkordančnikov, ki omogočajo podobne funkcije (glej npr. ta podrobni seznam), med najbolj priljubljenimi pa so AntConc (brezplačen) in WordSmith Tools (potreben je nakup licence), ki ju je mogoče uporabljati brez internetne povezave in ne vsebujeta predhodno naloženih korpusov, ter spletna konkordančnika BYU (za polno delovanje je potrebna brezplačna registracija) in SketchEngine (brezplačna akademska licenca), ki vsebujeta številne predhodno naložene korpuse za različne jezike. SketchEngine omogoča tudi ustvarjanje in označevanje lastnih korpusov.
2Večina sodobnih konkordančnikov omogoča naslednje funkcije, ki jih bomo uporabili tudi v tem gradivu:
- Konkordančni niz prikazuje vse zadetke iskane besede ali niza besed v korpusu ter njihovo sobesedilo. Konkordance, posamezne enote konkordančnega niza, so lahko razvrščene naključno ali glede na iskano besedo oziroma niz besed. Razvrstiti jih je mogoče tudi glede na levi ali desni kontekst, kar izpostavi značilne vzorce, v katerih se iskana beseda oziroma niz besed pojavlja.
- Frekvenčni seznami prikazujejo vse zadetke za izbrano korpusno poizvedbo, ki je lahko v obliki besede/besedne zveze ali določenega nabora metapodatkov. Zadetki so lahko razvrščeni po abecedi ali pogostosti, pripisan pa jim je tudi podatek o njihovi frekvenci. V nasprotju s konkordančnim nizom besedni seznami ne vsebujejo sobesedila zadetkov.
- Seznami ključnih besed izpostavljajo besede, ki v izbranem korpusu izstopajo v primerjavi z izbranim referenčnim korpusom.
- Seznami kolokacij vsebujejo nize besed, ki se v kombinaciji z iskano besedo pojavljajo pogosteje od naključnega.
3Na voljo so že številna navodila za uporabo konkordančnikov (npr. SketchEngine Quick Start Guide) in tečaji korpusnega jezikoslovja (npr. Corpus Linguistics: Method, Analysis, Interpretation). V tem gradivu se osredotočamo na prikaz uporabe konkordančnika NoSketchEngine in specializiranega korpusa za iskanje odgovorov na konkretna raziskovalna vprašanja na metodološko ustrezen način. Gradivo je namenjeno študentkam in študentom ter raziskovalkam in raziskovalcem s področja (digitalne) humanistike in družboslovja, ki jih zanima raziskovanje sociokulturnih pojavov prek jezikovne rabe.