1Za analizo parlamentarnih razprav bomo uporabili tematsko modeliranje, eno od tehnik rudarjenja besedil, ki se uporablja pri raziskovanju velikih količin podatkov. Za ustrezno izbiro metode raziskovanja, ki bo dala kakovostne rezultate, in za kritično interpretacijo rezultatov je nujno poznati delovanje ter prednosti in slabosti uporabljenih metod (prim. Shadrova, 2021). Ker bomo v naši analizi kot tehniko tematskega modeliranja uporabili latentno Dirichletovo dodelitev, sledi predstavitev delovanja tehnike in izsledkov nekaterih raziskav, pri katerih je bila le-ta uporabljena na parlamentarnem diskurzu.
2Tematsko modeliranje je priljubljena metoda za avtomatsko analizo besedil, na podlagi katere lahko iz korpusa izluščimo prevladujoče teme, ki se pojavljajo v preučevanih besedilih. Rezultat tematskega modeliranja je tematski model, ki ga sestavljajo teme, ki pa ne zaznamujejo dejanske tematike, o kateri govori besedilo, ampak so zgolj skupine besed, ki glede na matematično verjetnost sodijo skupaj in naj bi predstavljale isto tematiko. Raziskovalec pa mora nato ročno opredeliti oziroma poimenovati temo, ki naj bi jo te besede predstavljale.
3Za tematsko modeliranje korpusa je mogoče uporabiti različne tehnike oziroma algoritme (Vayansky in Kumar, 2020). Med najpogosteje uporabljenimi je tehnika LDA oziroma latentna Dirichletova dodelitev, ki jo bomo uporabili tudi v naši analizi. Tehniko so razvili Pritchard idr. (2000), za analizo besedil pa so jo predlagali Blei, Ng in Jordan (2003). Tehnika je izrazito primerna za obdelavo obsežnih zbirk besedilnih podatkov, ki jih zaradi velikosti ne moremo obdelati ročno.
4.1. Tehnika LDA
1LDA vključuje naslednje korake, izvedene v več ponovitvah:
- Algoritem najprej vsem besedam v besedilu naključno dodeli oznako teme.
| Beseda | Dokument | |||
| EPIDEMIJA | KRIZA | DAVEK | GOSPODARSTVO | |
| dok1 | tema 1 | tema 2 | tema 2 | tema 1 |
| dok2 | tema 1 | tema 1 | tema 2 | tema 1 |
| dok3 | tema 2 | tema 1 | tema 1 | tema 2 |
| dok4 | tema 1 | tema 2 | tema 2 | tema 2 |
- Algoritem prešteje, kolikokrat se določena tema pojavi v posameznem besedilu (leva tabela) in kolikokrat je določena tema pripisana posamezni besedi (desna tabela).
|
|
- Nato algoritem za posamezno besedo privzame, da ne pozna več njene teme.
| epidemija | kriza | davek | gospodarstvo | |
| dok1 | ? | tema 2 | tema 2 | tema 1 |
| dok2 | tema 1 | tema 1 | tema 2 | tema 1 |
| dok3 | tema 2 | tema 1 | tema 1 | tema 2 |
| dok4 | tema 1 | tema 2 | tema 2 | tema 2 |
- Za tem posodobi obe tabeli iz 2. koraka, tako da znova določi frekvenco določene teme v posameznih besedilih (leva tabela) in frekvenco določene besede v posameznih temah (desna tabela).
|
|
- Izračuna, kako močna je povezava med besedilom in temo (verjetnost teme v dokumentu: moder pravokotnik) ter temo in izbrano besedo (verjetnost besede v temi: rdeč pravokotnik).
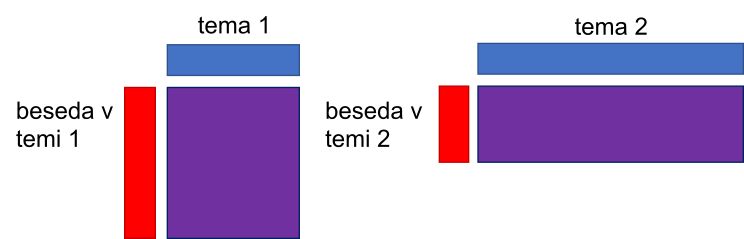
- Vijolični pravokotnik je zmnožek rdečega in modrega pravokotnika in predstavlja verjetnost, da beseda pripada določeni temi. Na podlagi slednje verjetnosti (oba vijolična kvadrata) nato tehnika določi, kateri temi bo pripadal dokument (zelena zvezda, ki, glede na izračunano verjetnost kombinacije besede in teme, predstavlja naključno dodelitev teme izbranemu dokumentu).
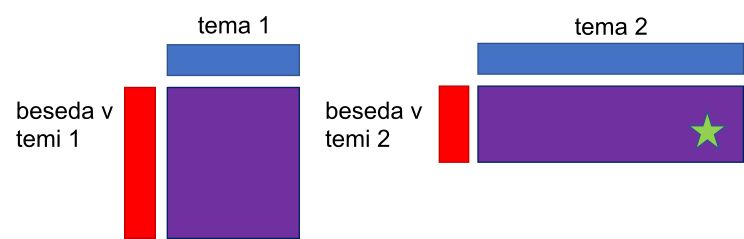
Na kratko, algoritem na podlagi verjetnosti (vijolična kvadrata) določi novo temo (zelena zvezda). Verjetnostna porazdelitev tem v besedilu se izračuna na podlagi Dirichletove porazdelitve, ki določa, da verjetnost nikoli ni ničelna. To pomeni, da ima vsaka beseda vsaj majhno možnost, da pripada tudi manj pogosti temi, oziroma da je v dokumentu prisotna tudi manj pogosta tema.
Ko besedi algoritem določi temo, posodobi tudi tabelo besedila-besede.
| epidemija | kriza | davek | gospodarstvo | |
| dok1 | tema 2 | tema 2 | tema 2 | tema 1 |
| dok2 | tema 1 | tema 1 | tema 2 | tema 1 |
| dok3 | tema 2 | tema 1 | tema 1 | tema 2 |
| dok4 | tema 1 | tema 2 | tema 2 | tema 2 |
- Glede na novo vrednost iz tabele v 6. koraku algoritem znova posodobi obe tabeli, torej tabeli teme-besedila in besede-teme.
| tema 1 | tema 2 | |
| dok1 | 1 | 3 |
| dok2 | 3 | 1 |
| dok3 | 2 | 2 |
| dok4 | 1 | 3 |
| tema 1 | tema 2 | |
| epidemija | 2 | 2 |
| kriza | 2 | 2 |
| davek | 1 | 3 |
| gospodarstvo | 2 | 2 |
- Postopek se ponavlja, dokler se dodelitve tem ne nehajo spreminjati. Končni rezultat je tematski model. Temo predstavlja skupina besed, ki se pogosto pojavljajo skupaj v besedilih.
2Zgoraj smo opisali verzijo LDA z Gibbsovim vzorčenjem. Orange namesto Gibbsovega vzorčenja uporablja metodo variacijske inference. Gibbsovo vzorčenje je veliko bolj natančno, medtem ko je variacijska inferenca hitrejša za večje podatke.
4.2. Značilnosti tehnike LDA
1LDA temelji na več predpostavkah. Prva je, da temo zaznamujejo besede, ki se v besedilih pogosto pojavljajo skupaj. To pomeni, da je LDA jezikovno neodvisna tehnika, saj besede združuje v skupine na podlagi njihove pojavitve v besedilu in ne na podlagi njihovega pomena. Isto metodo je torej mogoče uporabiti na podatkih v različnih jezikih. Obenem velja, da je lahko posamezna beseda uvrščena v več tem, vendar običajno z različno verjetnostjo.
2Druga predpostavka je, da se teme v korpusu pojavljajo različno pogosto in da so medsebojno neodvisne. LDA ne opredeli morebitne povezave med temami, pokaže pa verjetnost razporeditve tem v besedilu, pri čemer opredeli njihovo pomembnost v določenem besedilu. Posamezno besedilo običajno vsebuje več tem, vendar določena tema najpogosteje izstopa (tj. v glavno skupino besed algoritem razvrsti več besed kot v druge skupine besed oziroma teme).
3Tretja predpostavka je, da je število tem vnaprej določeno. To pomeni, da mora raziskovalec vnaprej določiti število tem, v katere naj algoritem razvrsti dokumente. Optimalno število tem za določeno besedilo je tisto, pri katerem je za dobljene skupine besed najlažje opredeliti smiselne teme, ki so še vedno informativne glede na zastavljeni raziskovalni problem. Zato raziskovalci običajno postopek tematskega modeliranja za vsako raziskavo posebej večkrat ponovijo z različnim številom tem, pri čemer ocenjujejo povednost skupin besed, ki jih je iz besedila izluščil algoritem. Nekateri si pomagajo tudi z dodatnimi statističnimi izračuni (prim. Smith in Graham, 2019). Čeprav se torej ustrezno število tem razlikuje od primera do primera, običajno število tem sega od 5 do 50 (Arun idr., 2010), veliko raziskav pa se odloči za 20 tem (Zhao idr., 2015; Gkoumas idr., 2018; Rosa idr., 2021).
4Četrta predpostavka je, da vrstni red besed v besedilu ni pomemben. LDA namreč deluje na podlagi t. i. vreče besed, ki ne upošteva jezikovne strukture in povezav med besedami. Ta predpostavka je problematična, saj je vrstni red besed ena ključnih značilnosti realnih besedil.
5Na rezultate pa ključno vpliva vrstni red besedil, saj tehnika v začetku besedilom naključno dodeli teme. Če se spremeni vrstni red, se bo tudi začetna dodelitev spremenila. Vrstni red besedil v smislu njihovega časovnega zaporedja prav tako lahko pomembno vpliva na značilnosti besedil (Vayansky in Kumar, 2020).
4.3. Predobdelava podatkov
1Za potrebe tematskega modeliranja morajo biti podatki ustrezno pripravljeni. To največkrat vključuje tokenizacijo (členitev na pojavnice, običajno besede, števila, ločila), lematizacijo (pripis osnovne oblike vsaki pojavnici) in oblikoskladenjsko označevanje (pripis besedne vrste vsaki pojavnici, npr. glagol). Slednje nam omogoča, da tematsko modeliranje izvedemo zgolj na določeni besedni vrsti. Raziskave namreč kažejo, da lematizacija in omejitev korpusa zgolj na samostalnike izboljšata tako hitrost algoritma kot njegove rezultate, in sicer z vidika koherence oziroma smiselne povezanosti besed v posameznih skupinah, zaradi česar jim je lažje pripisati temo (Martin in Johnson, 2015). Razlikovanje po oblikoskladnji lahko uporabimo tudi za iskanje odgovorov na različna raziskovalna vprašanja. Tako so na primer Van der Zwaan idr. (2016) tematsko modeliranje najprej izvedli na samostalnikih in tako pridobili teme, nato pa algoritem pognali še na glagolih, pridevnikih in prislovih, na podlagi česar so nato izluščili stališča parlamentarcev. Pred uporabo metode LDA iz korpusa običajno odstranimo tudi zelo pogoste besede, ki so lahko preveč splošne (npr. zaimki, predlogi) ali preveč specifične za preučevani žanr (npr. pozdravne besede, kot je spoštovani, v parlamentarnem korpusu), glede na izbrani raziskovalni problem pa lahko odstranimo tudi zelo redke besede, ločila, veliko začetnico ipd. (Smith in Graham, 2019).
4.4. Omejitve metode LDA
1Kot prvo omejitev lahko izpostavimo dejstvo, da LDA za uspešno delovanje potrebuje daljša besedila, saj temelji na porazdelitvah besed, ki za kratka besedila niso izrazite. Tako na primer LDA ni primerna tehnika za tematsko modeliranje tvitov, uporabniških komentarjev ali poezije. Čeprav jo je mogoče uporabiti tudi za analizo npr. objav na Facebooku (Serrano idr., 2019), se za tovrstna besedila priporočajo druge metode tematskega modeliranja (Albalawi idr., 2020; Morstatter idr., 2018). Čeprav so parlamentarni govori običajno dovolj dolgi za učinkovito uporabo metode LDA, pa lahko nekatere seje vključujejo tudi zelo kratke govore, ki jih je pred uporabo metode LDA dobro odstraniti (glejte poglavje 5.4).
2Druga omejitev je povezana s predpostavko, da so besede medsebojno neodvisne, prav tako pa tudi besedila in teme, kar je po eni strani jezikoslovno netočno, po drugi strani pa raziskovalcem onemogoča pregled nad korelacijami med besedami oziroma med besedili. Ta informacija pri mnogih raziskovalnih problemih sicer ni potrebna, zato tehnika LDA zadostuje. Če pa je ta informacija pomembna (npr. če nas zanima razvoj teme skozi daljše časovno obdobje), so na voljo druge metode tematskega modeliranja, npr. dinamično tematsko modeliranje (Müller-Hansen idr., 2021). Poleg tega LDA ne deluje dobro, če besedilo o neki temi ne govori koherentno, ampak jo omeni zgolj s par besedami. Po drugi strani pa tehnika dobro deluje za daljša, tematsko opredeljena besedila, na primer za novice, akademske članke, politične govore in določena prozna dela.
3Naslednja omejitev je vezana na število tem, ki ga mora raziskovalec določiti po lastni presoji in je običajno rezultat preizkušanja. Kot opozarjata Allen in Murdock (2020), bodo pri zelo velikem številu nekatere teme predstavljale zgolj zelo specifičen del enega od besedil v korpusu, zaradi česar je težje iskati tematske povezave med besedili. Kadar pa je število tem postavljeno zelo nizko, jih je običajno lažje interpretirati, vendar so najpogosteje teme zelo splošne in tako precej neinformativne za analizo.
4Kot zadnjo omejitev lahko omenimo težavnost interpretacije rezultatov tematskega modeliranja, vključno z načinom navajanja rezultatov v publikacijah. Ker so rezultat izolirane skupine besed, obstaja nevarnost, da raziskovalci v njih vidijo vzorec, ki ga pravzaprav ni, oziroma prepoznajo teme, ki so jih že v izhodišču pričakovali (Shadrova, 2021). Pri interpretaciji je zato pomembno, kakšno število besed upošteva raziskovalec, ko opredeljuje temo. Ta je lahko namreč precej drugačna, če raziskovalec sklepa o temi na podlagi prvih 10 ali prvih 30 besed, ki jih ponudi algoritem (Allen in Murdock, 2020). Pri interpretaciji skupin besed in opredeljevanju ter interpretaciji tem je zato nujno potrebno kvalitativno branje oziroma poznavanje izvirnih delov besedila, v katerih se izbrane besede pojavljajo, še posebej za skupinsko delo pa je priporočljivo oblikovati tudi smernice za odločanje.
5Tematsko modeliranje po metodi LDA torej ni hitra rešitev, ki bi raziskovalca lahko brez kritične presoje rezultatov privedla do kakovostnih zaključkov. Prav razumevanje omejitev je bistvenega pomena za uspešno uporabo tematskega modeliranja v raziskovalne namene. Kvantitativne, avtomatske metode analize torej lahko pomembno dopolnjujejo raziskovalčeve sposobnosti za analizo, vendar ne morejo nadomestiti človeške interpretacije (Grimmer in Stewart, 2013). Tematsko modeliranje omogoča pomembno prednost pred kvalitativnim branjem, in sicer možnost obdelave velike količine podatkov, kar raziskovalcem omogoča robustnejše posploševanje na podlagi rezultatov kot pri analizi, izvedeni na majhnem vzorcu (Jacobs in Tschötschel, 2019). Poleg tega postopek tematskega modeliranja omogoča večjo objektivnost rezultatov (Müller-Hansen idr., 2021), čeprav zaradi prej omenjenih omejitev, kot je opredelitev tem na podlagi skupine besed, tehnika ni v celoti objektivna. To je obenem tudi prednost te tehnike, saj algoritem ne poda neposrednih odgovorov, ampak raziskovalce sili v upoštevanje konteksta pri oblikovanju končnih rezultatov (Schmidt, 2012). Tematsko modeliranje vnaša tudi večjo sistematizacijo analize in omogoča sorazmerno večjo ponovljivost rezultatov (Jacobs in Tschötschel, 2019). Priljubljenost in aktualnost te tehnike za humanistične in družboslovne raziskave se kažeta tudi v velikem številu raziskav, ki tematsko modeliranje uporabljajo v svoji metodologiji (gl. poglavje 4.5).
4.5. Tematsko modeliranje parlamentarnih razprav
1V politologiji in drugih humanističnih in družboslovnih vedah, ki analizirajo velike količine realnih podatkov, se tematsko modeliranje vse bolj uveljavlja kot pomembna analitična tehnika, ki dopolnjuje ustaljene, kvalitativne pristope za analizo. Rezultati tematskega modeliranja namreč lahko služijo kot usmeritev za kvalitativno analizo (npr. identifikacijo relevantnih besedil o najbolj izstopajoči temi) ali pa že predstavljajo del končnih rezultatov. V tem poglavju predstavljamo nekaj primerov uporabe tematskega modeliranja parlamentarnih podatkov.
2S tematskim modeliranjem lahko izluščimo vsebinske tematike, o katerih se razpravlja v parlamentu. Schuler (2020) je na primer z metodo LDA analiziral razprave v vietnamskem parlamentu in rezultate povezal s temami iz novic, tudi pridobljenimi z LDA, ter seznamom področij pod neposrednim upravljanjem Komunistične partije (KP). S tem je raziskal, ali poslanci v avtoritarnih sistemih, kot je vietnamski, izražajo svoja stališča in aktivno razpravljajo glede pomembnih tem. Ugotovil je, da do dejanske razprave pride zgolj pri temah, ki ne pokrivajo področij, ki so v neposrednem upravljanju KP, pri čemer slednja spodbuja takšno razpravo zato, da lahko pritiska na vlado in ji obenem naprti odgovornost za posledice sprejetih ukrepov. Kadar pa tema razprave zadeva eno od področij, ki jo s svojimi odbori neposredno upravlja KP, slednja ne spodbuja javne razprave. Obenem je zanimiva njegova ugotovitev, da se tudi pri temah, ki so odprte za izmenjavo stališč, v razpravo ne vključujejo vsi poslanci, ampak predvsem tisti, ki niso člani KP in so bili za polni delovni čas kot predstavniki ljudstva izvoljeni na lokalni ravni.
3Za odkrivanje vsebinskih tematik v parlamentarnih razpravah sta tematsko modeliranje uporabila tudi Chizhik in Sergeyev (2021), ki sta analizirala približno tri desetletja govorov ruskih poslancev, da bi ugotovila, ali obstajajo povezave med dejavnostjo strank v parlamentu in skepticizmom javnosti glede večstrankarskega sistema kot temelja za demokracijo. Ugotovila sta, da stranke ruskega parlamenta svojo pozornost predvsem posvečajo zunanjim zadevam, gospodarstvu in razmerju moči med vejami oblasti, medtem ko se precej manj posvečajo drugim družbenim problemom. Pri tem njihove govore, še posebej to velja za uveljavljene stranke, v veliki meri zaznamuje ideološki in propagandistični diskurz.
4Tematsko modeliranje torej omogoča, da pridobimo splošen pregled nad gradivom, ki lahko zadošča, če je naš namen, na primer, opazovati izpostavljenost tematik, o katerih se razpravlja v parlamentu. Tematsko modeliranje pa lahko uporabimo tudi za pridobivanje bolj specifičnih rezultatov. Ker so parlamentarni korpusi običajno bogato označeni z metapodatki, lahko teme raziskujemo v razmerju do drugih spremenljivk (npr. spol, starost, pripadnost politični stranki, mandat itd.) in tako izluščimo tiste teme, ki najbolj razlikujejo med vrednostmi izbrane spremenljivke. Tako lahko na primer opazujemo, kako aktualna je bila določena tema skozi čas ali pri določeni stranki. Curran idr. (2018) so na primer z metodo LDA in analizo kompleksnih mrež razkrili teme razprav v novozelandskem parlamentu in jih povezali s poslanci ter njihovimi strankami, ki so te teme naslavljali v svojih govorih. Na ta način so izluščili prevladujoče teme razprav v posameznih obdobjih in jih interpretirali v povezavi z zunanjimi dogodki (npr. potres leta 2011). Poleg tega so na podlagi rezultatov opredelili, koliko zanimanja je določeni temi namenila posamezna stranka. Izkazalo se je, da je Laburistična stranka veliko bolj zavzeto razpravljala o nepremičninski krizi kot takrat vladajoča Nacionalna stranka. Rezultati so pokazali tudi, da je Nacionalna stranka zavzela glavnino razprave, medtem ko se je prispevek manjših strank skozi čas zmanjševal. Zmanjšala pa se je tudi specializacija parlamentarcev za različne teme, kar se kaže v velikem številu tem, ki jih naslavlja večina poslancev.
5Ena od možnosti uporabe metapodatkov pri tematskem modeliranju je predstavljena tudi v raziskavi, ki so jo izvedli de Campos idr. (2021). Metodo LDA so namreč uporabili za določanje tematskega profila španskih poslancev, ki odraža področja, ki jih ti pokrivajo v parlamentu. Metapodatke sta s pridom uporabila tudi Høyland in Søyland (2019), ki sta želela ugotoviti, ali je sprememba volilnega sistema leta 1919, ko je norveški politični sistem postal bolj odvisen od strankarske politike in poslanci niso imeli več toliko avtonomije kot pred reformo, vplivala na tematiko parlamentarnih razprav. Pri tem sta uporabila različico metode LDA, in sicer strukturno tematsko modeliranje (STM), ki poleg porazdelitve besed pri izračunu rezultatov sočasno upošteva tudi izbrane metapodatke. Ugotovila sta, da razporeditev tem jasno kaže, da institucionalna ureditev vpliva na delovanje parlamentarcev. Po reformi, ki je poudarila pomen strankarske politike, so postale teme, ki so izrazito kazale ideološke razlike med strankami, pogostejše, medtem ko so poslanci manj govorov namenjali neposredni kritiki drugih poslancev. Obenem so poslanci po reformi pogosteje razpravljali o temah splošnega zanimanja (npr. o izobraževalnem sistemu) in redkeje o temah, ki so neposredno obravnavale težave njihovih volilnih okrajev (npr. o izgradnji infrastrukture v nekem oddaljenem kraju).
6S tematskim modeliranjem lahko tudi raziščemo kontekst in nabor tem, s katerimi je povezan določen pojem. Müller-Hansen idr. (2021) so uporabili različico tehnike LDA, imenovano dinamično tematsko modeliranje (DTM), ki omogoča analizo tem skozi čas. S to metodo so analizirali sedemdeset let nemških parlamentarnih razprav o premogu, in tako raziskali, kako so se razprave o premogu spreminjale skozi čas4. Razprave iz zgodnjih let korpusa kažejo, da so poslanci premog dojemali kot gonilo gospodarskega razvoja in jamstvo energetske varnosti, medtem ko v zadnjih letih razprave o premogu predvsem govorijo o energetskem prehodu, postopni opustitvi premoga in razmahu obnovljivih virov energije. Obenem so raziskovalci ugotovili, da manjše in mlajše stranke (npr. Zeleni) v nemškem parlamentu pogosteje kot druge stranke govorijo o premogu v kontekstu energetskega prehoda in varovanja okolja.
7Namesto izbranega pojma lahko na podlagi rezultatov tematskega modeliranja opazujemo kontekst določene teme oziroma prepletanje tem. Blätte idr. (2020) so, na primer, želeli izvedeti, kako pogosto se o migracijah razpravlja v kontekstu skupne evropske politike. Z metodo LDA so ustvarili tematski model za parlamentarne razprave Avstrije, Francije, Nemčije in Nizozemske, izbrali tri teme, ki so najbolje predstavljale migracije oziroma evropske zadeve, nato pa izluščili vse govore, kjer sta se ti dve krovni temi križali. Raziskava je pokazala, da so bile razprave o migrantih v dveh večjih državah iz korpusa (Francija, Nemčija) bolj usmerjene navznoter. Še posebej v Nemčiji je evropski vidik skoraj izginil, medtem ko se je v manjših državah iz vzorca (Avstrija, Nizozemska) delež govorov, ki o migracijah razpravljajo z vidika evropskega odziva, povečal.
8V tem učnem gradivu se delno naslanjamo na metodologijo, ki so jo uporabili Curran in sodelavci (2018) v zgoraj omenjeni raziskavi novozelandskih govorov, pri čemer v naši analizi obravnavamo krajše časovno obdobje, zato podrobnejša delitev po letih ni smiselna. Kot je razvidno iz zgoraj opisanih raziskav, bi lahko analizo nadgradili s strukturnim tematskim modeliranjem, pri čemer bi upoštevali, na primer, strankarsko pripadnost govorcev in opazovali razlike med njimi. Lahko pa bi analizirali tudi celoten korpus ParlaMint-SI in z dinamičnim tematskim modeliranjem opazovali razlike tem skozi čas. Vendar je za primerjavo tem v dveh obdobji, pred in med epidemijo, tehnika LDA povsem ustrezna.
4. Diahrono analizo tem, torej razvoj tem skozi čas, je mogoče analizirati tudi le s tehniko LDA, vendar je pri tem treba za vsako časovno obdobje narediti ločen tematski model, interpretirati dobljene teme in jih nato primerjati med različnimi časovnimi obdobji. Tak pristop zahteva več ročnega, subjektivnega dela, kar lahko negativno vpliva na rezultate. Druga možnost za časovno analizo tem je dinamična nenegativna matrična faktorizacija (dynamic NMF) (Gkoumas idr., 2018), ki pa tematike med različnimi obdobji poveže zgolj posredno. (Müller-Hansen idr., 2021)