1To poglavje je razdeljeno na tri praktične naloge, v katerih s tematskim modeliranjem in nekaterimi vizualizacijami raziščemo vsebino parlamentarnih razprav pred in med epidemijo. Pri tem bomo odgovorili na naslednja vprašanja:
- v 1. nalogi: Katere teme zaznamujejo naše podatke?
- v 2. nalogi: O katerih temah so poslanci največ razpravljali?
- v 3. nalogi: Katere teme so izstopale med epidemijo v primerjavi s predepidemičnim obdobjem?
6.1. Teme parlamentarnih razprav
1V tem poglavju bomo za vzorec podatkov najprej pripravili številski opis, ki je potreben za izvedbo metode LDA, nato bomo teme izluščili in jih poimenovali, na koncu pa bomo preverili še, kako so teme razporejene po dokumentih in kako lahko poiščemo govore na izbrano temo.
6.1.1. Ustvarjanje besedilnih vektorjev
1Preden lahko izvedemo tematsko modeliranje, potrebujemo predprocesirane podatke in vektorsko reprezentacijo govorov. Predprocesiranje podatkov smo že opravili (glejte poglavje 5.4), vektorsko reprezentacijo pa izvedemo z gradnikom Bag of Words, ki naredi številski opis govorov, na podlagi katerega je nato mogoče izračunati porazdelitev besed po temah oziroma izvesti tematsko modeliranje govorov. Številski opis, ki ga pridobimo s tehniko vreče besed, predstavljajo besede v stolpcih, vrednosti pa izkazujejo število pojavitev posamezne besede v danem govoru. Vsak govor je tako predstavljen s svojim vektorjem, ki predstavlja njegovo vsebino. Pogostejša kot je neka beseda v govoru, bolj vektor tega govora kaže v smeri te besede.
2Vendar pa niso vse besede enakovredne. Nekatere besede v korpusu so lahko izrazito proceduralne in žanrsko specifične (glejte poglavje 5.4), nepolnomenske (npr. zaimki, vezniki) ali pa preprosto nespecifične za izbrani govor. Beseda hvala se, na primer, pojavi v tematsko zelo heterogenih govorih, saj se večina poslancev zahvali za predajo besede, zato tematsko gledano ni informativna. Besede v našem vzorcu zato želimo obtežiti tako, da bodo imele večjo težo take, ki so izrazito specifične za posamezni govor, nižjo težo pa take, ki se pogosto pojavljajo v vseh govorih. Taka obtežitev se imenuje TF-IDF, kar je angleška kratica za term frequency-inverse document frequency oziroma frekvenca izraza–inverzna frekvenca dokumenta (Jones, 1972), in je na voljo kot izbirna možnost v gradniku Bag of Words.
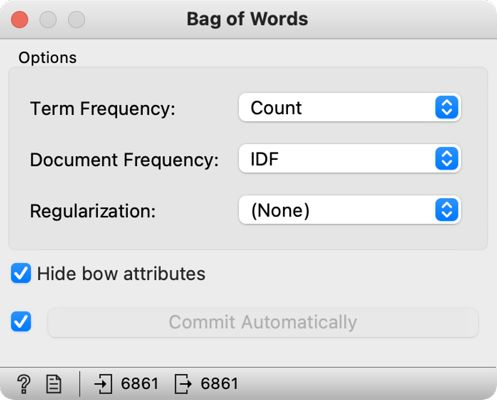
3Gradnik Bag of Words dodamo takoj za gradnikom Preprocess Text in ga nastavimo tako, da ohranimo možnost preprostega štetja besed (Count) v prvi vrstici (Term Frequency), v drugi vrstici (Document Frequency) pa izberemo IDF (Slika 11).
6.1.2. Luščenje tem
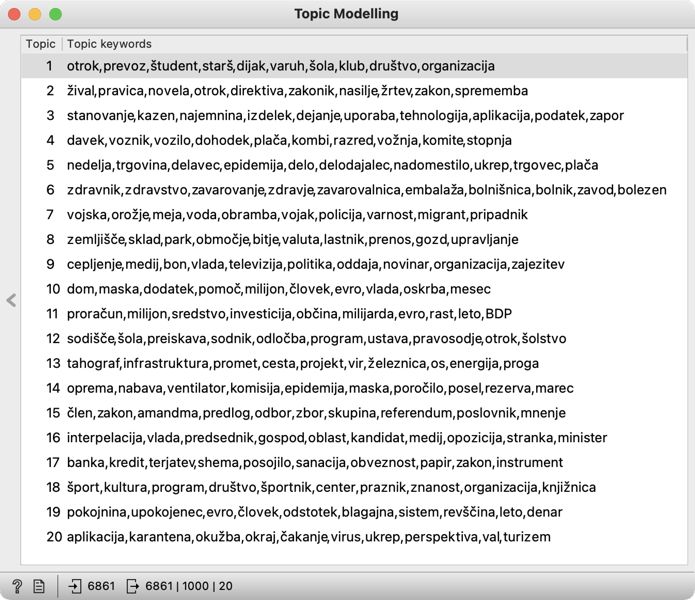
1Sedaj, ko smo pripravili vektorsko reprezentacijo govorov, lahko začnemo z luščenjem tematik. To bomo storili z gradnikom Topic Modelling, ki ga povežemo z Bag of Words in nastavimo tako, da izberemo metodo LDA (Latent Dirichlet Allocation) in določimo 20 tem (Number of topics). Izbira števila tem je sicer poljubna, vendar sorodne raziskave kažejo, da se pri večjih korpusih najbolje obnese 20 tem (glejte 4. poglavje). Na desni se izpiše dvajset skupin besed, ki zaznamujejo teme našega vzorca (Slika 12). Nekatere teme je enostavno poimenovati že na prvi pogled, medtem ko pri drugih krovna tematika ni povsem jasna. V naslednjem koraku bomo zato izvedli dodatno analizo, na podlagi katere bomo lažje opredelili teme.
2Pri tem koraku velja omeniti še, da je tehnika LDA stohastična, kar pomeni, da ob vsakem izračunu vrne drugačne rezultate, saj temelji na naključnem določanju izhodiščnih tem. To značilnost metode, ki omejuje ponovljivost raziskav, v programu Orange zaobidemo z uporabo enotne začetne točke, kar omogoča, da uporabniki za iste podatke dobijo enake rezultate.
1Poskusite sami: uporabite različna števila tem, npr. 5 in 10. Ali z manjšim številom tem dobite boljše rezultate? Kaj pa se zgodi ob uporabi precej večjega števila tem, npr. 50?
6.1.3. Opredelitev tem
1LDA za vsako temo vrne 10 besed, ki so najpogosteje povezane z njo.15 A kot smo videli, te besede niso nujno dovolj informativne, da bi omogočale opredelitev tematike. Zato si pri opredeljevanju lahko pomagamo z gradnikom LDAvis (Sievert in Shirley, 2014). Bistvena prednost te vizualizacije je, da besede oceni na podlagi relevantnosti, ki predstavlja razmerje med specifičnostjo besede v določeni temi in specifičnostjo besede v celotnem korpusu. Vrednost parametra lambda, ki ga v gradniku nastavljamo z drsnikom Relevance, lahko izbiramo med 0 in 1, pri čemer 1 prikaže besede glede na specifičnost besede v temi (kot jih vidimo v gradniku Topic Modelling), 0 pa glede na njihovo pogostost v celotnem korpusu. Specifičnost besede v celotnem korpusu imenujemo tudi dvig (lift), ki predstavlja razmerje med verjetnostjo besede v temi in verjetnostjo besede v korpusu.
2Gradnik LDAvis torej povežemo z gradnikom Topic Modelling. Pri tem moramo paziti, da v LDAvis podamo prave vhodne podatke. Gradnik namreč potrebuje tabelo zastopanosti besed v temah, ki je dostopna v signalu All Topics. Povezavo uredimo tako, da dvakrat kliknemo povezavo med gradnikoma, nato pa povežemo signala All Topics in Topics (Slika 13).
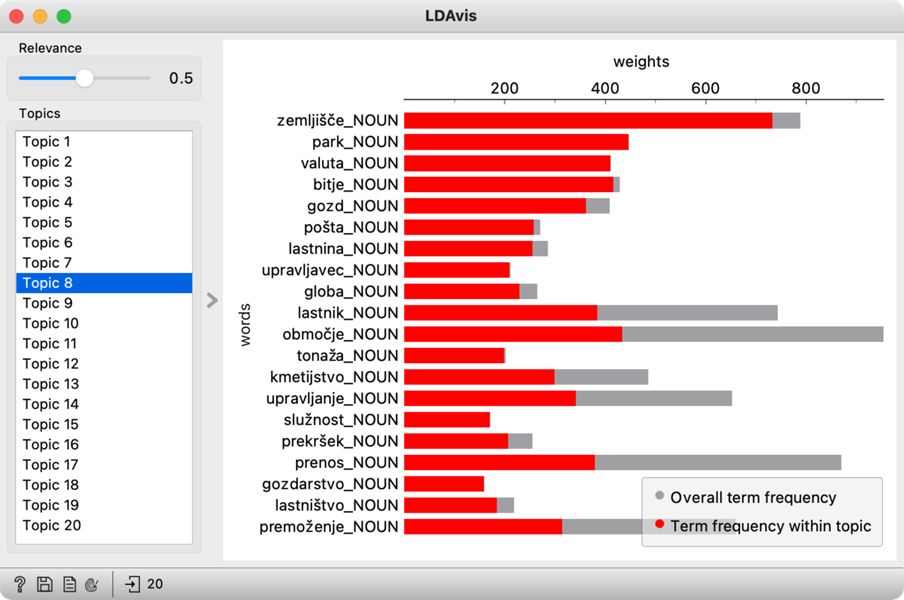
3LDAvis privzeto prikaže besede, razvrščene uravnoteženo, torej z enakim razmerjem med specifičnostjo besede v temi in specifičnostjo besede v korpusu, kar v praksi običajno da dobre rezultate.
4Z nastavljeno relevantnostjo dobimo drugačen, bolj informativen nabor besed, kot smo ga lahko videli v osnovnem gradniku Topic Modelling (Slika 14). Zdaj je očitno, da tema 8 govori o upravljanju prostora, tema 16 o političnih sporih in medijskem poročanju, tema 18 je mešanica tem o kulturi, športu in znanosti.
1Poskusite sami: poljubno premaknite drsnik relevantnosti v desno in levo. Pri kateri nastavitvi je za skupine besed najlažje opredeliti temo?
5Tako pregledamo vse teme. Za boljšo preglednost rezultatov lahko nadomestimo generična poimenovanja tem (npr. Topic 1) z ustreznimi pomenskimi oznakami (npr. T1: prevoz otrok). Za ta korak moramo na gradnik Topic Modelling najprej pripeti gradnik Select Columns, nanj pa še Edit Domain.
6Najprej odpremo gradnik Select Columns, kjer vidimo celoten nabor spremenljivk, vključno s frekvencami besed, ki smo jih za potrebe tematskega modeliranja ustvarili z gradnikom Bag of Words. Frekvenc besed ne potrebujemo več, zato jih odstranimo tako, da v razdelku Features na desni s tipkama Ctrl+A (Cmd+A) izberemo vse spremenljivke in jih prenesemo na levo stran, ki je namenjena spremenljivkam, ki jih želimo prezreti. Na levi strani v filter vpišemo Topic, s čimer poiščemo spremenljivke, ki označujejo teme (Topic 1, Topic 2 itd.), jih izberemo in prenesemo nazaj na desno stran, ki je namenjena spremenljivkam, ki jih želimo obdržati v tabeli (Slika 15).
7Nato odpremo gradnik Edit Domain, v katerem bomo izvedli dejansko preimenovanje. S seznama na levi izberemo prvo temo in na desni strani v polju Name določimo njeno ime, npr. T1: prevoz otrok (Slika 16). Poimenovanje tem nam pomaga pri interpretaciji vizualizacij, s katerimi bomo teme raziskali v nadaljevanju.
8Ko poimenujemo vse teme, dobimo seznam tem, o katerih so razpravljali poslanci od januarja 2019 do julija 2020. Ni presenetljivo, da na seznamu tem najdemo epidemiološke ukrepe in zdravstvo, medtem ko je morda nekatere druge teme, npr. prevoz otrok, davek na vozila ali šport in kultura, težje umestiti v prostor in čas, če nam aktualno dogajanje tistega časa ni znano. V grobem vidimo, da teme pokrivajo področja večine ministrstev, med drugim pravosodje, notranje zadeve, finance, zdravje, socialne zadeve in infrastrukturo. Obenem pa je za razumevanje takratnih prednostnih nalog tak seznam zanimiv tudi z vidika manjkajočih področij, ki bi jih sicer lahko pričakovali na seznamu tem parlamentarnih razprav, saj jih pokrivajo specifična ministrstva (npr. zunanje zadeve). Dejstvo, da npr. zunanjih zadev ni na seznamu tem, sicer ne pomeni, da poslanci o tej temi sploh niso razpravljali, nakazuje pa, da o njej ni bilo toliko razprave, da bi se uvrstila med 20 najizrazitejših tem za naš vzorec.
9Tak seznam tem nam torej omogoča hiter pregled nad temami, ki so zaznamovale parlamentarno razpravo v preiskovanem obdobju, vendar pa ne razkriva dodatnih informacij, npr. o kateri temi je bilo največ razprave, kako so teme med sabo povezane oziroma kako so razporejene po obdobjih. Za odgovore na ta vprašanja je treba rezultate tematskega modeliranja dodatno analizirati, kar bomo storili v naslednjih poglavjih. Pred tem pa si bomo ogledali še, kako so teme razporejene po govorih. Na ta način lahko preverimo kontekst govorov in po potrebi prilagodimo poimenovanja tem, obenem pa je to eden od načinov, kako izluščimo govore, v katerih izbrana tema prevladuje.
1Poskusite sami: poimenujte vse teme z ustrezno nadpomenko. Nekatere teme bo težje opredeliti. Pri teh si lahko pomagate z gradnikom Corpus Viewer, s katerim poiščete ustrezno besedo in raziščete njen kontekst.
6.1.4. Zastopanost tem po govorih
1Zaradi zakonitosti tematskega modeliranja (glejte 4. poglavje) govore običajno zaznamuje več kot ena tema, vendar so teme različno močno zastopane. Zastopanost oziroma verjetnost tem po govorih je izražena v razponu od 0 do 1, pri čemer 1 pomeni, da je tema v največji meri prisotna v govoru, 0 pa, da tema sploh ni prisotna. V praksi najpogosteje srečamo vmesne vrednosti. Ker imamo torej opravka z vrednostmi v istem razponu in ker želimo primerjati zastopanost tem med sabo, je najprimernejša vizualizacija toplotni diagram. Ustvarimo ga tako, da gradnik Heat Map povežemo z gradnikom Edit Domain.
2V diagramu je vrednost ponazorjena z barvo: visoke vrednosti so označene z rumeno in belo (oziroma drugo barvo na desnem robu lestvice), nizke vrednost pa z modro (oziroma drugo barvo na levem robu lestvice). Vsak stolpec v diagramu predstavlja posamezno temo, vsaka vrstica pa govor. Govori so v diagramu razvrščeni v takem vrstnem redu, kot smo jih naložili v program, zaradi česar je trenutno diagram precej nepregleden, vendar lahko to z nekaj nastavitvami popravimo.
3Najprej bomo govore, ki imajo podobno izražene teme, združili med sabo. Opravka imamo namreč z velikim številom govorov (6861), zato se vizualizacija raztegne v višino. V tem primeru lahko podobne govore predstavimo z eno vrstico in tako poskrbimo za kompaktnejšo postavitev. To storimo z možnostjo Merge by k-means, ki s postopkom metode k-voditeljev združi podobne govore med sabo. Prednastavljena vrednost je 50, mi pa jo bomo povečali na 150, saj je naših govorov veliko in ne želimo izgubiti preveč podrobnosti.
4Vizualizacija je tako že bolj pregledna, vendar bi bila še bolj informativna, če bi bile podobne vrstice blizu ena drugi. Pozor, sedaj vrstice niso več posamezni govori, temveč skupine podobnih govorov. Vrstice organiziramo s še enim postopkom odkrivanja gruč, in sicer s hierarhičnim razvrščanjem v skupine, ki ga nastavimo v razdelku Clustering, kjer pri možnostiRows izberemo Clustering (opt. ordering).
5Izriše se precej lažje berljiv diagram (Slika 17), ki ima na levi strani dendrogram oziroma drevesno strukturo podobnosti govorov, ki kaže povezave med gručami, obenem pa je priročen za natančno izbiro želene skupine govorov. V prejšnjem poglavju smo ugotovili, da krovna tematika za določeno temo ali pa interpretacija nekaterih tem, npr. šport in kultura, ni popolnoma jasna. S tem diagramom lahko enostavno izberemo želene govore in podrobneje analiziramo njihovo vsebino.
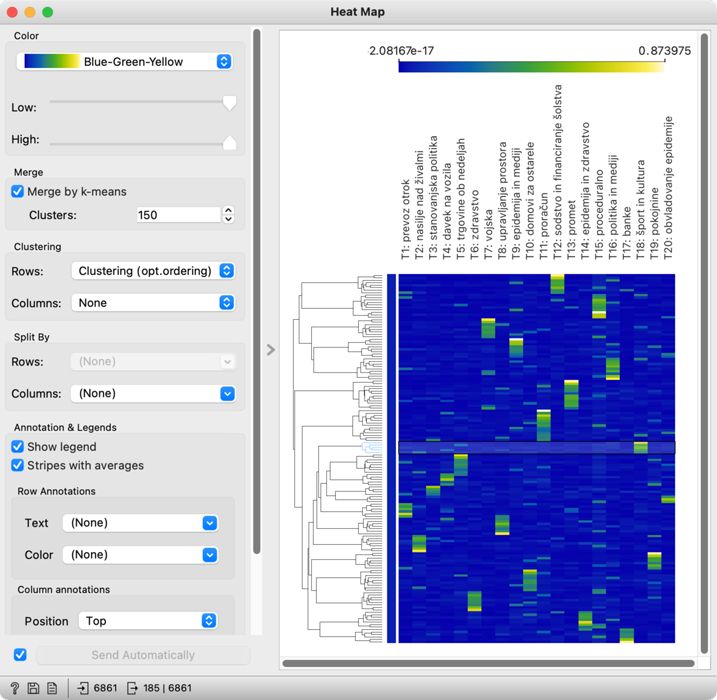
6Kot primer bomo izbrali temo T18: šport in kultura, ki jo predstavlja izbrana gruča v diagramu. Govore označimo tako, da izberemo vejo dendrograma, kjer je tema najbolj izrazita (rumene ali zelene barve) . Tako bo ta podmnožica govorov na voljo na izhodu gradnika. Zdaj na gradnik Heat Map pripnemo gradnik Corpus Viewer in si v njem preberemo izbrane govore.
7Ugotovimo lahko, da govori obravnavajo različne teme, npr. izdajo potrdil o opravljenih izobraževanjih, založniško dejavnost ter financiranje vrhunskih športnikov. Na tak način smo torej potrdili poimenovanje teme (ki je sicer nabor več podtem), obenem pa smo iz celotnega vzorca podatkov izluščili zgolj govore na izbrano temo, ki jih nato lahko uporabimo za nadaljnje analize.
8Pri interpretaciji tematskega modeliranja je nujno upoštevati, da govora ne zaznamuje zgolj ena tema, temveč je v vsakem govoru prisotnih več tem z različno verjetnostjo, kar lahko opazimo tudi pri temi T11: proračun. Če govore izberemo in jih pozorno preberemo, opazimo, da govori obravnavajo različne pristope k rebalansu proračuna, od povečanja sredstev za Urad za Slovence v zamejstvu in po svetu do financiranja domov za ostarele. Pravzaprav je to razvidno že iz diagrama, kjer vidimo, da je v nekaterih govorih v izbrani gruči precej močno izražena tudi tema T10: domovi za ostarele. Toplotni diagram torej odlično pokaže tudi primere tematskih presekov, kar je pomembno upoštevati, če to metodo uporabljamo zgolj za izbiro govor na določeno temo, ki jo želimo podrobneje raziskati. Na presek tem lahko kliknemo v diagramu in preberemo govore, ki se dotikajo obeh tem hkrati. Presek govorov o proračunu in domovih za ostarele predstavljajo govori o znižanju oskrbnine ter o uveljavitvi Zakona o dolgotrajni oskrbi.
1Poskusite sami: izberite govore, ki govorijo o epidemiji, in jih preglejte.
6.2. Najizrazitejše teme in povezave med njimi
1Sedaj poznamo razporeditev tem po govorih. Videli smo, da govore zaznamuje več tem hkrati, zato nas zanima, kako so te teme v posameznih govorih med seboj povezane. Poleg tega nas zanima, katere teme v našem vzorcu najbolj izstopajo. Na obe vprašanji najlažje odgovorimo s tematsko karto, na kateri so teme razporejene glede na njihovo zastopanost in razmerja do drugih tem.
2Tematsko karto bomo izdelali z gradnikom MDS. MDS je kratica za multidimensional scaling oziroma večrazsežnostno lestvičenje. Ta vizualizacija na podlagi vhodnih podatkov poskuša najti tak prikaz v ravnini, da povezane teme ležijo skupaj, nepovezane pa narazen. Pri postopku MDS se povezanost med temami izračuna glede na pomembnost besed v temah. Visoka povezanost med temami tako odraža zelo podobno porazdelitev besed med temami, pri čemer so lahko nekatere besede med temami celo deljene.
3Povezavo med gradnikoma Topic Modelling in MDS nastavimo tako, da povežemo All Topics v Data. Na začetku vidimo zgolj sive točke v ravnini, ki predstavljajo teme. Za lažjo interpretacijo bomo točkam dodali oznake. To storimo tako, da pri možnosti Labels izberemo spremenljivko Topics. Kot lahko vidimo, so točkam pripisane zgolj prvotne oznake tem, ne pa tudi poimenovanja, ki smo jih dodali, zato si moramo pri interpretaciji pomagati s seznamom tem, ki ga pripravimo ročno (Tabela 1).
| Izvirno | Preimenovano |
| Topic 1 | T1: prevoz otrok |
| Topic 2 | T2: nasilje nad živalmi |
| Topic 3 | T3: stanovanjska politika |
| Topic 4 | T4: davek na vozila |
| Topic 5 | T5: trgovine ob nedeljah |
| Topic 6 | T6: zdravstvo |
| Topic 7 | T7: vojska |
| Topic 8 | T8: upravljanje prostora |
| Topic 9 | T9: epidemija in mediji |
| Topic 10 | T10: domovi za starejše |
| Topic 11 | T11: proračun |
| Topic 12 | T12: sodstvo in financiranje šolstva |
| Topic 13 | T13: promet |
| Topic 14 | T14: epidemija in zdravstvo |
| Topic 15 | T15: proceduralno |
| Topic 16 | T16: politika in mediji |
| Topic 17 | T17: banke |
| Topic 18 | T18: šport in kultura |
| Topic 19 | T19: pokojnine |
| Topic 20 | T20: obvladovanje epidemije |
4Nastavili bomo tudi velikost točk, in sicer tako, da bo ustrezala zastopanosti teme (ki je vsota verjetnosti teme v govorih, utežena z dolžino govorov). Možnost Size nastavimo na Marginal Topic Probability. Za boljšo preglednost pa pri možnosti Color prav tako izberemo Marginal Topic Probability.
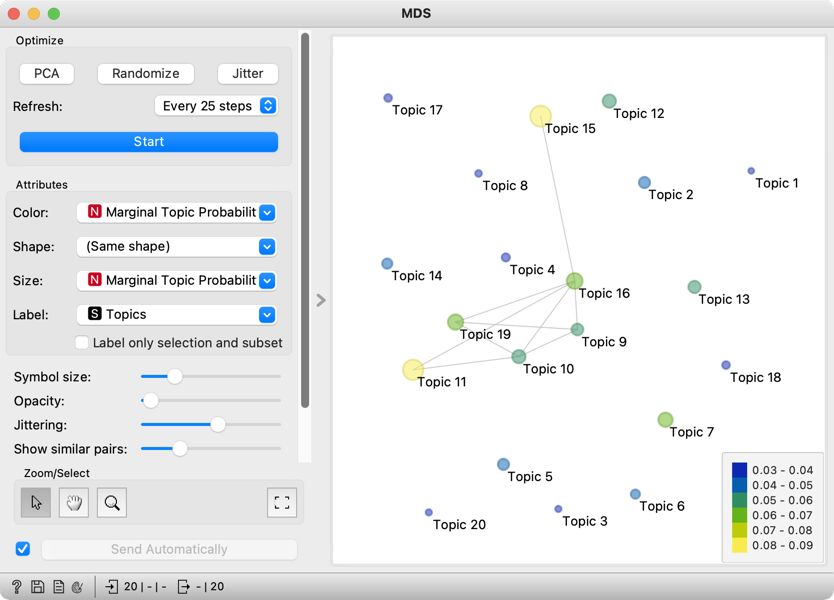
5Tematska karta s položajem točk kaže podobnost tem, velikost in barva točk pa njihovo zastopanost v našem vzorcu govorov (Slika 18). Kadar so si teme podobne, vendar točke zaradi omejitev dvodimenzionalne vizualizacije ležijo daleč narazen, je ta podobnost izražena s premico, ki povezuje ti dve točki. Vidimo, da sta najbolj zastopani obsežni temi 15 (proceduralno) in 11 (proračun), najmanj pa tematsko ozke teme 1 (prevoz otrok), 3 (stanovanjska politika) in 20 (obvladovanje epidemije).
6Močna zastopanost teme 11 (proračun) ni presenetljiva, saj je posledica pogostih razprav o rebalansu proračuna kot odgovoru na epidemiološke razmere (Vlada Republike Slovenije, 2020). Blizu nje ležita tudi temi 10 (domovi za starejše) in 19 (pokojnine), kar kaže, da se je o domovih za starejše in pokojninah razpravljalo tudi v kontekstu razporejanja davkoplačevalskega denarja. Ti dve temi (T10 in T19) sta si blizu tudi ena drugi, kar pa zopet ni presenetljivo, saj obe govorita o starejši populaciji.
7Blizu teme, ki zaznamuje razprave o proračunu, ležita tudi temi 9 (epidemija in mediji) in 16 (politika in mediji), ki sta obenem povezani med sabo. Te povezave (med temama 9 in 16) ni težko potrditi, če smo vsaj malo seznanjeni z dogajanjem v času epidemije, ko so mediji odigrali ključno vlogo pri obveščanju javnosti o najnovejših ukrepih, obenem pa so bili pod hudimi pritiski politike. Zgolj na podlagi vizualizacije pa je težje interpretirati povezavo med temama 16 (politika in mediji) in 11 (proračun). Da bi lažje razumeli, na kakšen način sta ti dve temi povezani, si lahko ogledamo govore, ki izkazujeta podobno zastopanost obeh tem.
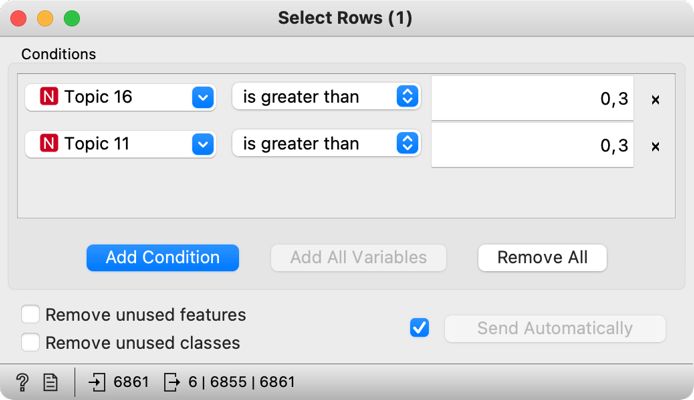
8Govore na preseku obeh tem si ogledamo tako, da najprej ustvarimo podmnožico govorov, ki imajo močno izraženi obe temi, torej T16: politika in mediji in T11: proračun. To storimo z gradnikom Select Rows, ki ga povežemo z gradnikom Topic Modelling. V gradniku nastavimo dva pogoja, in sicer Topic 16 is greater than 0.3 in Topic 11 is greater than 0.3 (Slika 19). Tako bomo izbrali zgolj govore, v katerih sta temi 16 in 11 izraženi z več kot 30-odstotno verjetnostjo.16
9Select Rows nato povežemo v gradnik Corpus Viewer, v katerem preberemo izbranih šest govorov, ki predstavljajo presek tem o proračunu ter politiki in medijih (Slika 20). Iz govorov je razvidno, da gre pri tem za strankarska prerekanja o rebalansu proračuna.

1Poskusite sami: Na enak način raziščite, kako sta povezani tema 9 in tema 11.
6.3. Teme pred in med epidemijo
1Ugotovili smo, katere teme v našem vzorcu najbolj izstopajo, zdaj pa nas zanima, katere teme so najbolj značilne za obdobje pred epidemijo in med njo. Razliko med obdobjema (ki sta označena kot podkorpusa Reference in COVID) bomo raziskali v gradniku Box Plot. Ta vizualizacija, v slovenščini znana tudi kot škatla z brki, kaže porazdelitve spremenljivk ter omogoča njihovo enostavno primerjavo po kategoričnih spremenljivkah (npr. spol, datum, stranka).
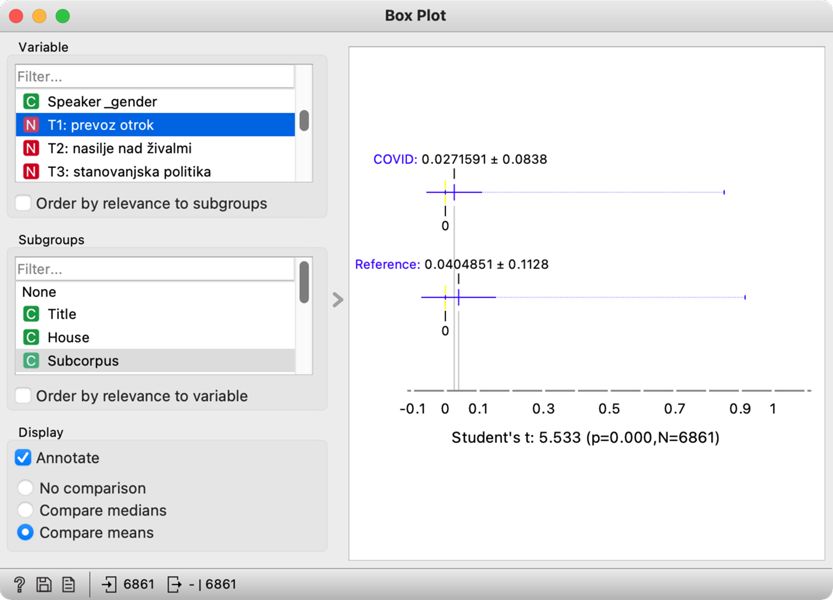
2Box Plot povežemo z gradnikom Edit Domain, saj bodo tako med rezultati že poimenovane teme. Ker želimo obdobji primerjati med sabo, v spodnjem razdelku na levi strani izberemo spremenljivko Subcorpus, v zgornjem razdelku pa kar temo T1: prevoz otrok. Na desni se prikažeta dve škatli z brki, zgornja za obdobje med epidemijo (COVID), spodnja pa za obdobje pred epidemijo (Reference) (Slika 21). Iz vizualizacije lahko razberemo, da so bile razprave na temo sodstva pogostejše pred epidemijo kot pa med njo. Obenem nam rezultat statističnega testa, ki je naveden pod vizualizacijo, potrjuje, da gre za statistično značilno razliko, njegova vrednost p je namreč nižja od 0,05. Na podlagi tega lahko zaključimo, da je bila tema o sodstvu bolj značilna za predepidemično obdobje.
3Na tak način bi lahko pregledali porazdelitev za vsako temo posebej, vendar bi bilo to precej časovno zamudno. Ker trenutno nismo osredotočeni na eno samo temo, ampak bi radi ugotovili, pri katerih temah se kažejo največje razlike med obdobjema, si bomo pomagali z možnostjo Order by relevance to subgroups pod razdelkom Variable. Tako bomo samodejno razvrstili spremenljivke glede na njihovo vrednost statističnega testa. Na vrhu bodo torej prikazane tiste spremenljivke, ki za izbrano razdelitev, ki smo jo določili v razdelku Subgroups (v našem primeru Subcorpus), izkazujejo največje razlike.
4Povsem na vrh razdelka Variable so uvrščene spremenljivke, kot so Title, From, To in Meeting. Gre torej za spremenljivke, ki izkazujejo izrazito različno porazdelitev med podkorpusoma Reference in COVID, vendar to ni presenetljivo, saj so vse te spremenljivke časovno zamejene, kar je bil tudi kriterij za oblikovanje obeh podkorpusov (glejte poglavje 3.3). Za naše potrebe je zanimiv vrstni red tem, ki sledijo tem prvim spremenljivkam.
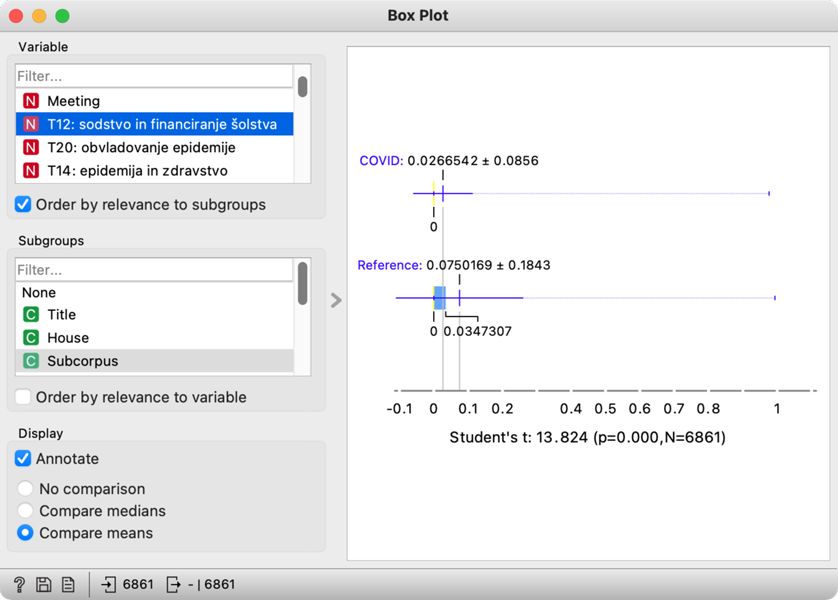
5Najvišje na seznamu sta temi T12: sodstvo in financiranje šolstva (Slika 22) in T20: obvladovanje epidemije. Ko ju izberemo, vizualizacija na desni pokaže, da so poslanci o sodstvu govorili več pred epidemijo, o obvladovanju epidemije pa, nepresenetljivo, med epidemijo. Rezultat študentovega t-testa (13,824, p<0,05), naveden pod vizualizacijo, obenem potrjuje, da gre za statistično pomembno razliko med obdobjema in da sta torej temi pogostejši v določenem času. Glede na okoliščine tak rezultat ni presenetljiv, kaže pa na zanesljivost metode za podobne raziskave. Sledita temi T14: epidemija in zdravstvo in T2: nasilje nad živalmi (prva izkazuje večjo pogostost v epidemičnem, druga pa v predepidemičnem času). Tudi tukaj se kaže statistično značilna razlika pri zastopanosti posamezne teme med obdobjema.
6Dejstvo, da sta temi o epidemiji bolj izraziti v COVID podkorpusu, pravzaprav ni presenetljivo. Bolj kot kaj drugega to potrjuje uporabnost tematskega modeliranja za podobne raziskave.
7Teme lahko podrobneje raziščemo s pomočjo gradnikov Select Rows in Corpus Viewer. Select Rows povežemo na Edit Domain. V Select Rows izberemo spremenljivko »T14: epidemija in zdravstvo« in nastavimo pogoj is greater than 0.7, s čimer bomo izbrali tiste govore, ki imajo zastopanost teme višjo kot 0,7 (več kot 70 % verjetnost, da je tema prisotna v govoru). Izbrane govore nato lahko pogledamo v gradniku Word Cloud.
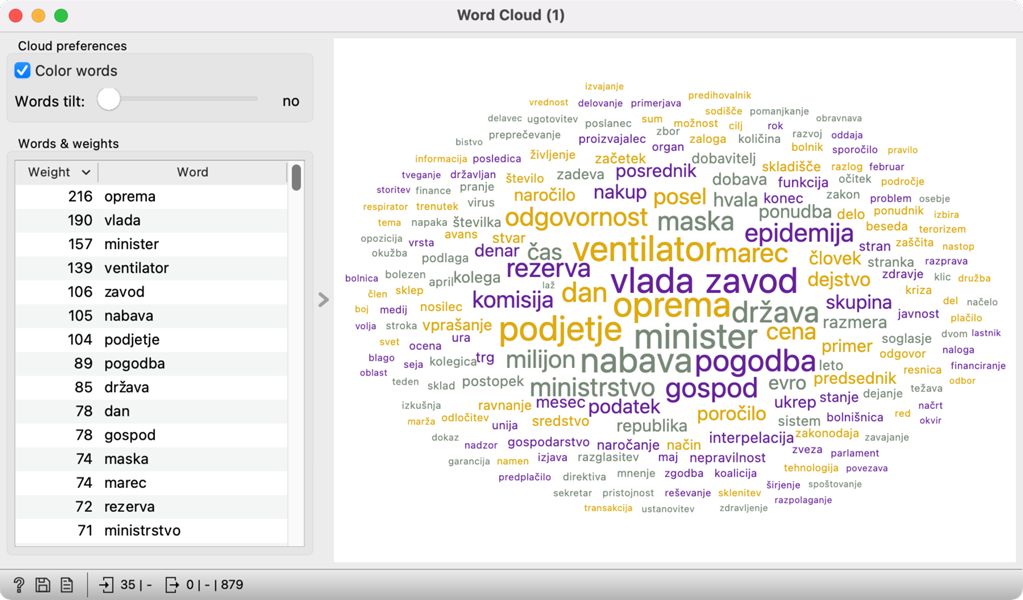
8Vidimo, da je govora zlasti o pogodbah za nabavo opreme, delu vlade in ministrov v času epidemije, vlogi podjetij za nakup opreme, na primer ventilatorjev, ter o Zavodu za blagovne rezerve (Slika 23). Veliko poudarka pri reševanju epidemije je zlasti na dobavi opreme, birokratski odgovornosti za nakup ter vlogi države pri zagotavljanju dobave. Ministrstvo za zdravje je že 3. 2. 2020 pričelo z ugotavljanjem zalog zaščitne in medicinske opreme, med drugim tudi ventilatorjev (RS RS, 2021), 2. 4. 2020 pa je Državni zbor za seji sprejel Zakon o interventnih ukrepih za zajezitev epidemije COVID-19 in omilitev njenih posledic za državljane in gospodarstvo (DZ RS, 2020).
1Poskusite sami: Na enak način, kot smo primerjali podkorpusa Reference in COVID, primerjajte med sabo tematsko porazdelitev v govorih opozicije in koalicije.
15. Možno je, da dobite nekoliko drugačne rezultate, kot so navedeni v gradivu. LDA je namreč generativni model, ki deluje naključno. Na svojem računalniku bi morali vedno znova dobiti enake rezultate, medtem ko se rezultati lahko razlikujejo med različicami programa Orange ter med operacijskimi sistemi.
16. Mejo pri 30 odstotkih smo izbrali, ker je to najnižja vrednost, ki vrne vsaj nekaj dokumentov. Pri tem se je treba zavedati, da je meja precej nizka, torej dokumenti izkazujejo nizko zastopanost teme. Vrednost lahko poljubno prilagajate.