1S tem poglavjem se začne praktični del učnega gradiva. Poglavje nas bo vodilo vse od namestitve programa ter uvoza in kontrolnega pregleda osnovnih podatkov do izdelave vzorca za analizo in predprocesiranja podatkov.
2Za prenos in namestitev programa Orange, vključno s programom Miniconda, ki je del namestitvenega paketa za Orange, boste potrebovali približno 1 GB prostora na disku. Za prenos datotek ParlaMint boste potrebovali 2,3 GB prostora. Upoštevajte, da je tematsko modeliranje računsko zahteven proces, zato bo morda delovanje računalnika upočasnjeno, sploh če uporabljate napravo z malo delovnega pomnilnika (RAM).
5.1. Namestitev in uporaba programa Orange
1Analizo bomo izvedli v odprtokodnem in prostodostopnem programu Orange v3.32.0, ki temelji na programskem jeziku Python (Demšar idr., 2013). Program je namenjen podatkovni analitiki, razširitev Text (v1.10.0) pa ponuja poseben nabor orodij za rudarjenje besedil. Orange je osnovan na vizualnem programiranju, kar pomeni, da potek analize določimo tako, da korake analize oziroma tako imenovane gradnike sestavljamo v analitski delotok.
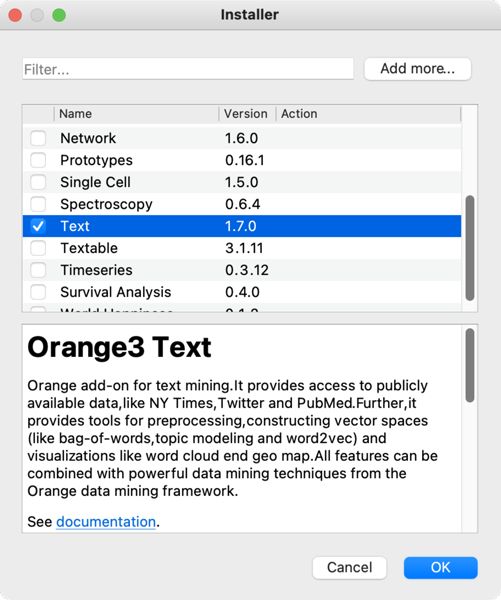
2Program najprej s spletne strani orangedatamining.com prenesemo na računalnik. Preneseno programsko datoteko odpremo in sledimo navodilom za namestitev. Nato program odpremo in naložimo še razširitev Text. To storimo tako, da izberemo zavihek Options in v spustnem meniju kliknemo Add-ons. Odpre se okno, kjer obkljukamo polje Text in namestitev razširitve potrdimo s klikom gumba OK (Slika 1).
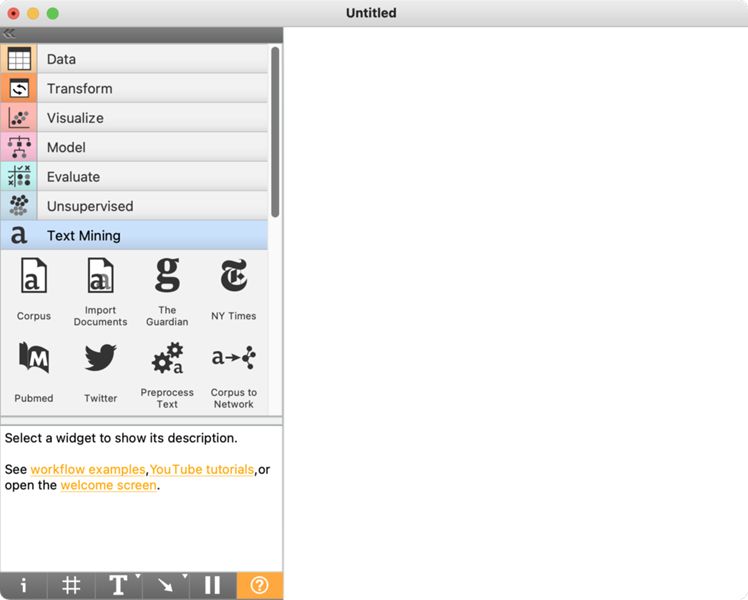
3Po namestitvi moramo znova zagnati program5. Ko se program odpre, se v levem meniju prikaže zavihek Text Mining, ki vsebuje različne gradnike (npr. Corpus, Bag of Words), ki so namenjeni analizi besedil (Slika 2). Na desni strani je belo polje, ki ga imenujemo platno (canvas). Nanj zlagamo gradnike (widgets), ki jih povezujemo v analitski delotok.
4Gradnike na platno dodajamo tako, da jih povlečemo iz menija na levi in spustimo na platno, ali pa z desnim klikom na platno odpremo spustni meni, vtipkamo ime gradnika, npr. Corpus, in ga s tipko Enter dodamo na platno. Če gradnik dvokliknemo, se odpre okno z nastavitvami. Vsak gradnik ima vhod ali izhod oziroma oboje, kar je označeno s črtkano črto ob strani gradnika. Vhod v gradnik je na levi, izhod pa na desni strani. Analiza v Orangeu vedno poteka od leve proti desni, nikoli obratno.
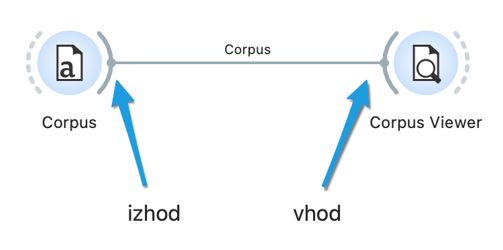
5Z enakim postopkom, kot smo dodali gradnik Corpus, dodajmo še gradnik Corpus Viewer. Če ga dvokliknemo, se odpre prazno okno. Gradnik namreč še ni prejel podatkov za obdelavo. Podatke pošljemo v gradnik tako, da z miško povežemo gradnika med sabo od desne črtkane črte gradnika Corpus do leve črtkane črte gradnika Corpus Viewer (Slika 3). Ta gradnik z dvoklikom znova odpremo in tokrat pojavno okno prikazuje podatke.6
6V učnem gradivu bomo sestavili delotok, s katerim bomo izvedli tematsko modeliranje parlamentarnih govorov in teme dodatno raziskali z vizualizacijami. Celoten delotok si lahko prenesete, vendar priporočamo, da sledite postopnim korakom v gradivu in sosledje gradnikov sestavite sami, saj boste tako najbolje razumeli posamezne faze analize.
5.2. Prenos in uvoz podatkov v Orange
1Korpus ParlaMint-SI obsega parlamentarne govore med leti 2014 in 2020. V praktičnem delu nas bo zanimala primerjava govorov tik pred in med epidemijo COVID-19, zato podatke najprej zamejimo na primerljivo dolgi obdobji pred in med epidemijo. Ker epidemično obdobje, ki je zajeto v korpusu ParlaMint-SI, vključuje devet mesecev (november 2019–julij 2020, Erjavec idr. 2022), bomo uporabili tudi podobno dolgo obdobje tik pred začetkom pandemije, in sicer od januarja 2019 do oktobra 2019.7
2Pri analizi bomo uporabili slovenski del jezikoslovno označenega korpusa parlamentarnih podatkov ParlaMint 2.1 (gl. poglavje 3.3). Parlamentarni govori s pripisanimi jezikoslovnimi oznakami so zapisani v formatu CoNLL-U. Da bomo lažje začeli, so podatki za potrebe tega učnega gradiva že pripravljeni in si jih prenesemo na računalnik.8 , 9
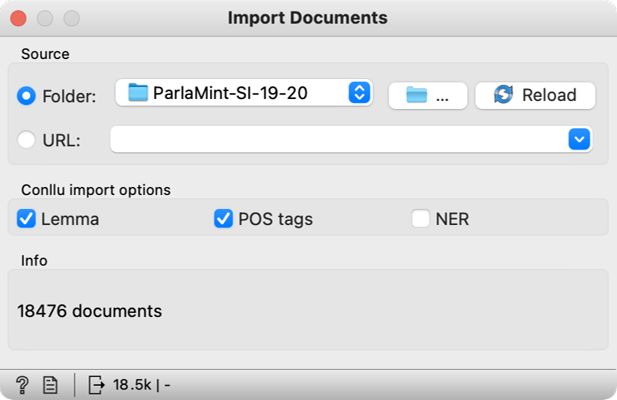
3Na platno dodamo gradnik Import Documents. Z dvoklikom odpremo okno za nastavitve in v prvi vrstici določimo mapo, v katero smo shranili podatke (Slika 4). Uvoza ni treba posebej potrjevati, zgodi se samodejno, ko določimo mapo. Malo nižje obkljukamo tudi možnosti Lemma in POS tags. Tako bomo poleg govorov uvozili tudi leme in oblikoskladenjske oznake. Govor posameznega poslanca za posamezno sejo bo predstavljen kot posamezen dokument. V spodnjem delu okna nas program obvesti, da smo uvozili 18.476 dokumentov oziroma govorov.
4Za boljše razumevanje strukture podatkov si na kratko oglejmo značilnosti formata CoNLL-U. Gre za obliko formata TSV, v katerem so vrednosti ločene s tabulatorjem in ki se na področju obdelave naravnega jezika uporablja za zapisovanje jezikoslovno označenih besedil, saj zaradi razporeditve besedila in oznak po stolpcih omogoča enostavno računalniško obdelavo. V tem formatu vsaka poved predstavlja svoj sklop, besedilo pa je tudi vertikalizirano, kar pomeni, da so besede zapisane ena pod drugo, kar omogoča jasen pregled nad pripisanimi jezikoslovnimi oznakami. Vsaka poved ima na začetku navedene tudi metapodatke (npr. ID govora, ID povedi in besedilo) (Slika 5).

5.3. Pregled podatkov
1Preden začnemo z analizo, se je dobro najprej prepričati, da so naloženi podatki res pravi. To bomo storili z gradnikom Corpus Viewer, ki ga dodamo na platno in ga od leve proti desni povežemo s prejšnjim gradnikom. Corpus Viewer odpremo z dvoklikom in prikaže se seznam dokumentov, ki v našem primeru predstavljajo posamezne govore (Slika 6). S klikom na seznam si lahko ogledamo tudi druge govore, če pa med klikanjem pridržimo tipko Shift, lahko prikažemo več govorov hkrati.
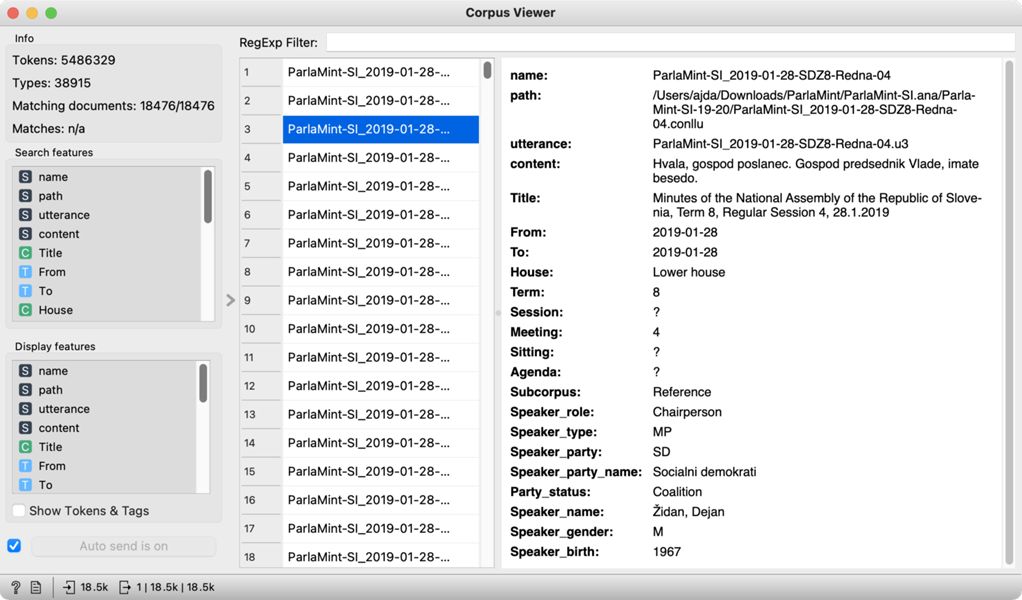
2V levem zgornjem kotu vidimo osnovne informacije o korpusu: število pojavnic (tokens) in različnic (types)10 ter število govorov (matching documents), ki ustrezajo iskalnemu filtru (regexp filter), če bi ga uporabili. Ker je filter trenutno prazen, so prikazani vsi govori (18476/18476). Zadnji podatek (matches) je število zadetkov iskalnega izraza, ki bi ga lahko vnesli v polje RegExp Filter.11
3V pregledovalniku na desni strani vidimo številne metapodatke12 o govorih in govorcih, s katerimi je opisana vsebina korpusa.13 Vsak govor je označen z imenom seje, ki ji pripada (name), in unikatno oznako (utterance), pri čemer zadnja številka izkazuje zaporedno številko govora v dotični seji. Celoten govor si lahko preberemo pod spremenljivko content. Pomemben je tudi podatek o podkorpusu (Subcorpus), ki označuje časovno obdobje, v katerem je bil govor podan (Reference označuje govore pred novembrom 2019, COVID pa od novembra 2019).
4Sledijo podatki o govorcu – njegova vloga (Speaker role), ki je lahko ali predsedujoči ali običajni govorec, funkcija (Speaker type), ki je lahko ali poslanec ali gost, pripadnost politični stranki (Speaker party), parlamentarni status stranke (Party status), ki je lahko opozicija ali koalicija, ime govorca (Speaker name), spol (Speaker gender) in leto rojstva (Speaker birth).
5.4. Priprava vzorca in predprocesiranje
1Kot smo videli v 3. poglavju, za parlamentarni diskurz velja jasna struktura, ki vključuje številne značilne fraze, npr. besedo ima poslanec …, hvala za besedo, spoštovana gospa ministrica, potrjujem dnevni red ipd. Nekatere fraze, ki urejajo potek razprave, so še posebej značilne za predsedujoče parlamentarnim sejam, druge so zgolj del vljudnostnega izražanja. Zaradi svoje narave so take fraze v parlamentarnih korpusih zelo pogoste, vendar za tematsko analizo niso zanimive, temveč bi predstavljale zgolj šum v rezultatih, zato jih želimo izločiti iz vzorca. V celoti jih je sicer nemogoče izločiti na enostaven, avtomatiziran način, vseeno pa lahko njihovo število pomembno omejimo. To bomo storili tako, da bomo pripravili vzorec podatkov, iz katerega bomo izločili vse govore predsedujočih in govore, ki so krajši od 50 besed (Slika 8).
»Hvala lepa. V skladu s poslovnikom bi želel v imenu poslanske skupine 30 minut odmora pred glasovanjem«.(Brane Golubović, redna seja, 6. marec 2019)
2To odločitev smo sprejeli po ročnem pregledu dela korpusa, v katerem se je izkazalo, da so taki govori večinoma zgolj zahvale ali medklici. Podobno filtriranje uporabljajo tudi sorodne raziskave (Curran idr., 2018). Čeprav taki govori seveda niso nujno le proceduralne narave, so, zato ker so kratki, v vsakem primeru manj primerni za tematsko modeliranje z metodo LDA, ki za dobre rezultate potrebuje daljša besedila (glejte 4. poglavje). Poleg tega bomo iz vzorca za analizo izločili tudi vse govore posameznikov in posameznic, ki v parlamentu lahko nastopajo kot gosti.
5.4.1. Odstranjevanje neželenih govorov
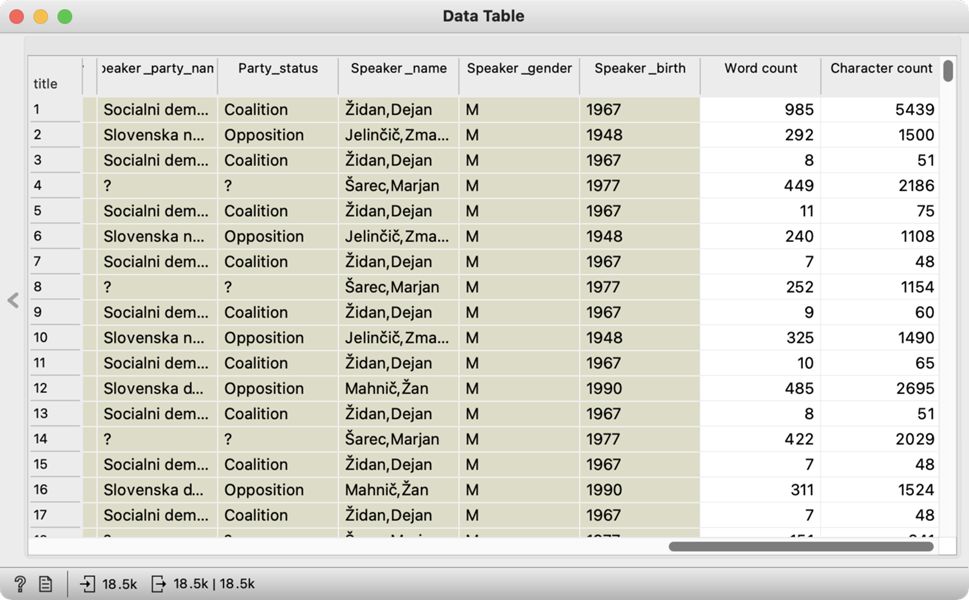
1Za oblikovanje vzorca potrebujemo gradnika Statistics in Select Rows. Na platno dodamo gradnik Statistics in ga povežemo z gradnikom Import Documents, pri čemer ohranimo prednastavitve, na podlagi katerih gradnik prešteje število besed (word count) in število znakov (character count) v govorih. Gradnik Statistics podatkom doda stolpca s številom besed in znakov, kar si lahko ogledamo tako, da dodamo gradnik Data Table, ga odpremo in se pomaknemo skrajno desno (Slika 7). Tako dobimo podatek o dolžini govorov, kar nam omogoča, da zdaj z gradnikom Select Rows izberemo zgolj tiste, ki ustrezajo našim merilom glede dolžine.
2Ko dodamo gradnik Select Rows (Slika 8), ga povežemo z gradnikom Statistics, odpremo in nastavimo tri pogoje (pogoje dodajamo z gumbom Add condition):
- s prvim pogojem določimo najmanjšo dolžino govora – spremenljivko Word count omejimo z možnostjo is greater than in vpišemo želeno minimalno dolžino, v našem primeru 50, s čimer bomo v vzorec vključili zgolj govore, ki imajo 51 besed ali več;
- z drugim pogojem iz vzorca izločimo predsedujoče sejam – spremenljivko Speaker role določimo s parametrom is in parametrom Regular;
- s tretjim pogojem v vzorcu ohranimo zgolj govore poslancev – spremenljivko Speaker type določimo s parametrom is in parametrom MP, s čimer izločimo govore gostov.
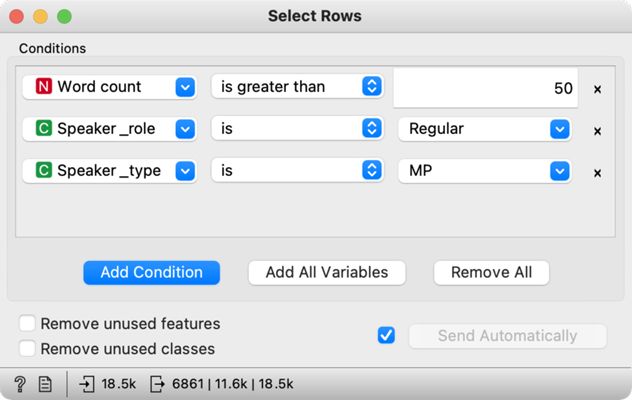
3Na spodnjem robu gradnika Select Rows vidimo, da se je število govorov skrčilo na 6861 (s prejšnjih 18.476; podrobne podatke dobimo, če kliknemo številke na spodnjem robu).
5.4.2. Odstranjevanje neželenih besed
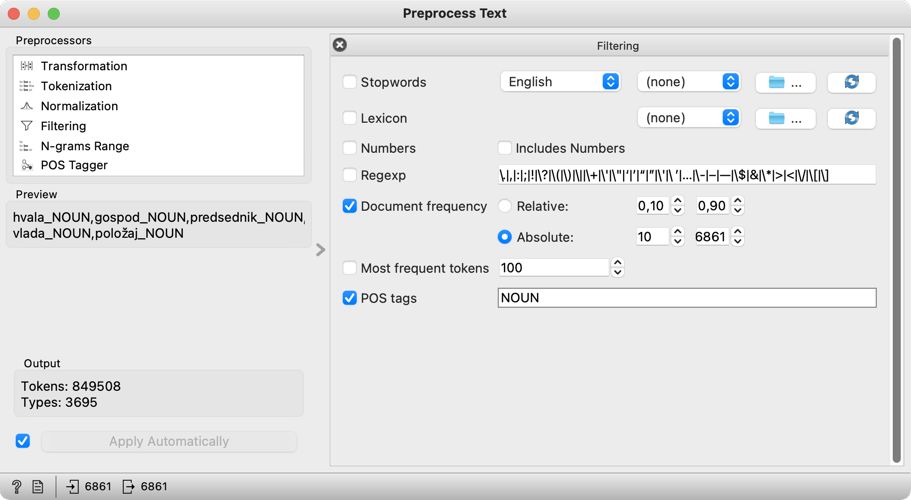
1Za dobre rezultate tematskega modeliranja je pomembna tudi predobdelava podatkov (glejte poglavje 4.3.). To storimo s filtriranjem v gradniku Preprocess Text, ki ga dodamo na platno, vendar ga še ne povežemo. Najprej bomo nastavili vse parametre, saj se bo tako postopek izvedel bolj gladko. Kljub temu upoštevajte, da je ta korak računsko zahteven in zato lahko tudi precej zamuden. Ko torej odpremo gradnik Preprocess Text, se prikažejo privzeti izbrani koraki za predobdelavo besedila, katerih vrstni red in nastavitve je mogoče poljubno spreminjati. Naši podatki so že tokenizirani in besede transformirane v zapis z malo začetnico (prim. poglavje 5.3). Zato koraka Transformation in Tokenization odstranimo s klikom križca levo zgoraj (Mac OS) oziroma desno zgoraj (Windows).14 Ostane korak Filtering, pri katerem bomo spremenili nekaj nastavitev (Slika 9):
- izključimo možnost Stopwords – te možnosti, ki je namenjena odstranitvi nepolnopomenskih besed, kot so zaimki, vezniki, predlogi ipd., ne potrebujemo, ker se bomo osredotočili zgolj na samostalnike;
- obkljukamo možnost Document frequency in kot mero izberemo absolutno vrednost (Absolute), pri kateri nastavimo razpon od 10 do 6861 (število vseh govorov) – tako bomo pri analizi prezrli besede, ki se pojavijo v manj kot desetih govorih, kar pomeni, da bomo iz analize izločili zelo redke besede, ki ne vplivajo na oblikovanje specifičnih tem;
- obkljukamo tudi možnost POS tags, kar lahko storimo, ker so naši podatki že oblikoskladenjsko označeni (glejte poglavje 3.3) – ta možnost je privzeto nastavljena tako, da pri poznejših analizah upošteva zgolj samostalnike (noun) in glagole (verb), a ker so se samostalniki izkazali kot najkoristnejši pri tematskem modeliranju (Martin in Johnson, 2015), za analizo ohranimo zgolj to besedno vrsto, glagole (verb) pa izbrišemo.
2Sedaj Preprocess Text povežemo z gradnikom Select Rows.
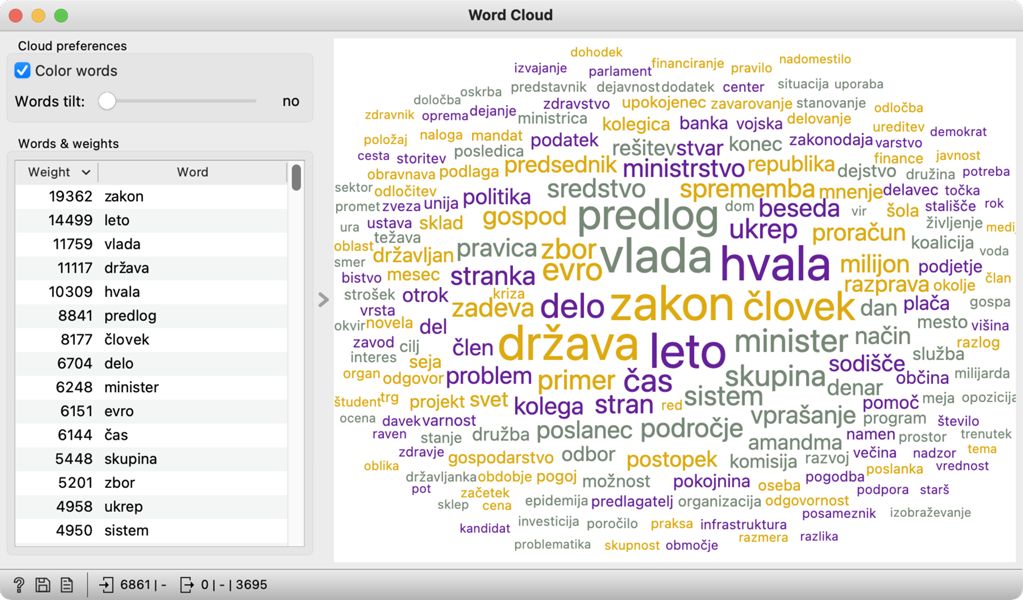
3Najpogostejše besede našega vzorca lahko preverimo v oblaku besed. Izdelamo ga z gradnikom Word Cloud, ki ga pripnemo na gradnik Preprocess Text. V oblaku najdemo zgolj samostalnike, pri čemer je velikost besede v oblaku sorazmerna z njeno frekvenco (Slika 10). Prikazane besede zelo jasno odražajo parlamentarni žanr besedil. Na seznamu na levi vidimo, da je najpogostejša beseda zakon, ki se v korpusu pojavi 19.362-krat. Ker je parlament glavno zakonodajno telo v državi, tak rezultat seveda ni presenetljiv.
4Predprocesiranje je pomemben del obdelave besedilnih podatkov, vendar je potrebno vsak korak jasno utemeljiti. Vsaka odločitev namreč vpliva na končne rezultate, kar je potrebno upoštevati tudi pri interpretaciji. Omenimo še, da v Orangeu filtriranje ne spreminja izhodiščnih podatkov. Po predprocesiranju imamo torej še vedno na voljo izhodiščni korpus iz gradnika Select Rows ter dodano informacijo o pojavnicah iz gradnika Preprocess Text.
5. Če ste Orange že kdaj uporabljali, svetujemo, da ponastavite gradnike, in sicer z možnostjo Options Reset widget settings. Tako boste lažje sledili analizi, kot je opisana v tem učnem gradivu.
6. Prikazani so prednaloženi podatki.
7. Predhodno smo preverili, da sta tako časovno zamejeni obdobji primerljivi tudi z vidika količine govorov in sej, ki jih vsebujeta.
8. Če bi želeli analizirati celoten korpus ali uporabiti drugačno časovno obdobje, je celoten korpus na voljo v repozitoriju CLARIN.SI v datoteki s podatki ParlaMint-SI.ana.tgz.
9. Potrebujemo tako datoteke v formatu CoNLL-U kot tudi tiste v formatu TSV. Datoteke CoNLL-U vsebujejo jezikoslovno označene govore, datoteke TSV pa metapodatke o govorcih in govorih (glejte poglavje 3.3).
10. Število pojavnic označuje število vseh besed, števil in ločil, ki so v korpusu. Število različnic pa je število unikatnih pojavnic v korpusu.
11. Pri določanju iskalnega izraza lahko uporabimo pravila regularnih izrazov, ki nam omogočajo iskanje zelo specifičnih zadetkov oziroma hkratno iskanje različnih oblik z enim iskalnim izrazom. Tako lahko npr. z iskalnim izrazom epidemij* zajamemo vse sklanjatve besede epidemija.
12. Nekateri metapodatki lahko manjkajo, če so bile izvorne parlamentarne evidence nepopolne. Jezikoslovne oznake so bile pripisane avtomatsko, kar pomeni, da so v korpusu možne napake, vendar so te minimalne, saj so bila uporabljena orodja z visoko natančnostjo: lematizacija 98–99 % pravilnost, oblikoslovne oznake 94–77 %, skladenjske oznake 87–94 % (Erjavec idr., 2022).
13. Nabor metapodatkov je enak za celotno družino korpusov ParlaMint (glejte poglavje 3.3), vendar vsi korpusi ne vsebujejo vseh metapodatkov.
14. Če želimo onemogočiti posodobitev ob vsaki spremembi parametra, odznačimo možnost Apply Automatically levo spodaj, nato pa, ko smo vnesli vse želene nastavitve, kliknemo Apply.